Each student chooses their data source. Anyone wanting to continue with the Seattle data can do so.
Software to be used is Processing or JavaScript(p5, deck.gl).
Please provide as with any relevant information pertaining to your project such as brief concept description, sketch, sequel query, data, screenshots, analysis, and code.
As with the previous assignment, the three critical issues to address are:
Innovation in content: your query question and outcomes. How original, engaging, unusual, your query, or your approach to the query may be, and how interesting the data may be. The data has to be multivariate, and granular (meaning a lot of data) so that we can see patterns forming in the data.
Innovation in design/ form: The design needs to go beyond our demos. Areas of exploration are in how you use space, form, colors, data organization, timing, interaction, coherence, elegance, etc.
Interaction with the Data: Each student selects their own data but you can also continue with the Seattle data if you want. Each student selects the topic of what the final project will address.
Computation: The third evaluation is the computational component. First of all, the code needs to work. Special consideration will be for unusual, elegant expression, utilizing functions, algorithms, etc that you can introduce to the class.
4 Final Project
-
zhangweidilydia
- Posts: 12
- Joined: Fri Jan 19, 2018 11:09 am
Re: 4 Final Project
3d Data Visualization of News searched in Centre Pompidou Library
from March 13th - March 26th
Better to view on PDF Data Analysis
*Raw Data
This is the raw data given by Pompidou Centre Library.
Basically it shows 5 di erent kinds of data:
They are SEARCH ID, TIMESTAMP, DOMAIN, URL AND TITLE
Some Facts I found from the Raw Data:
1. The timestamp each day is from 6:00 AM – 17:00PM
2. The seached times on each day from March 17th - March 22th is generally evenly distributed. However the number of search time on March 20th is nearly two times of others
3. Many of the domains visitors used are repetitive.
Counts/Dates
Dates/Time
Thurs, I found out it will be interesting to include the counts of search times each day, while speci cally emphasize di erent time on each day to see it’s relationship with the content of news being searched.
I deleted session.id column, url column.
*Organized Data
Organized data includes:
DATE, TIME, DOMAIN,TITLE AND COUNTS
Visual Inspiration
A public reading library, the Bpi is designed for anyone seeking information or training, for personal, professional or academic pur- poses.
Open until 10 pm every day except Tuesdays, in 2013 the Public In- formation Library recorded 1 462 779 entrées – a gure that is par- ticularly high for a library, which situates it in the top 10 of the most heavily visited Parisian institutions, along with the Arc de Triomphe and the Tour Montparnasse.
The comparison stops there. The operation of a major public library is not the same as a monument or a tourist site: the returning visitor rate is particularly high and subject to speci c kinds of variations, which may be seasonal (the low ows in summer alternate with the crowds during examinations), weekly (the saturation peaks on week- ends contrast with the smooth ows on Friday afternoons) and daily (o -peak hours as of 6 pm).
Pompidou Centre a complex building in the Beaubourg area of the 4th arrondissement of Paris, near Les Halles, rue Montorgueil, and the Marais. It was designed in the style of high-tech architecture by the architectural team of Richard Rogers and Renzo Piano, along with Gianfranco Franchini. (wiki)
Concept Development
sketchI
sketch II
Data Visualization
from March 13th - March 26th
Better to view on PDF Data Analysis
*Raw Data
Basically it shows 5 di erent kinds of data:
They are SEARCH ID, TIMESTAMP, DOMAIN, URL AND TITLE
Some Facts I found from the Raw Data:
1. The timestamp each day is from 6:00 AM – 17:00PM
2. The seached times on each day from March 17th - March 22th is generally evenly distributed. However the number of search time on March 20th is nearly two times of others
3. Many of the domains visitors used are repetitive.
Thurs, I found out it will be interesting to include the counts of search times each day, while speci cally emphasize di erent time on each day to see it’s relationship with the content of news being searched.
I deleted session.id column, url column.
*Organized Data
DATE, TIME, DOMAIN,TITLE AND COUNTS
Visual Inspiration
Background information of BpiTHE BUILDING’S MOST FAMOUS STRUCTURAL FEATURE IS ITS “INSIDE-OUT” CONSTRUCTION, WHICH EMPHASIZ- ES THE IDEA OF THE CULTURAL CENTER AS A MACHINE AND PLACES THE MECHANICAL SYSTEMS ON THE EXTE- RIOR, TO KEEP THE INSIDE UNENCUMBERED AND OPEN
RESEARCH
A public reading library, the Bpi is designed for anyone seeking information or training, for personal, professional or academic pur- poses.
Open until 10 pm every day except Tuesdays, in 2013 the Public In- formation Library recorded 1 462 779 entrées – a gure that is par- ticularly high for a library, which situates it in the top 10 of the most heavily visited Parisian institutions, along with the Arc de Triomphe and the Tour Montparnasse.
The comparison stops there. The operation of a major public library is not the same as a monument or a tourist site: the returning visitor rate is particularly high and subject to speci c kinds of variations, which may be seasonal (the low ows in summer alternate with the crowds during examinations), weekly (the saturation peaks on week- ends contrast with the smooth ows on Friday afternoons) and daily (o -peak hours as of 6 pm).
Pompidou Centre a complex building in the Beaubourg area of the 4th arrondissement of Paris, near Les Halles, rue Montorgueil, and the Marais. It was designed in the style of high-tech architecture by the architectural team of Richard Rogers and Renzo Piano, along with Gianfranco Franchini. (wiki)
Concept Development
Data Visualization
Last edited by zhangweidilydia on Thu Mar 15, 2018 4:30 pm, edited 8 times in total.
Re: 4 Final Project
Movie City
- 3D data visualization based on genres of movies
Dataset
I use the dataset from TMDB(website same as IMDB but it provides open API to access to its database), which contains basic information of 4804 movies from 1930s to 2010s. The raw dataset that I pull down from TMDB API looks like this:
After running a script to preprocess the raw data and delete unnecessary features, I have the organized dataset I'd like to use for my final project. It's pretty clear and straightforward. Every movie contains following features: budget, genres, keywords, popularity, release_date, revenue, runtime, tagline, title and ranking(vote_average).
Sketch
While processing nested json files within "genre" column, I found out that almost 90% movies are cross-genre. I thought it would be so much fun to visualize data based on such a complicated, nested and elegant feature. According to my statistical results, there are 19 single genres in total: "Foreign", "Documentary", "Western", "Mystery", "Family", "Animation", "Crime", "Comedy", "Action", "Adventure", "Drama", "Science Fiction", "Romance", "Horror", "Thriller", "Fantasy", "Music", "War", "History". For every movie, it has one main genre and zero or several subgenres. The best way to visualize the nested data is using the tree. A tree has 19 tree branches and every branch grow its own sub branches as sub genres.
A radial tree takes up the least area and expresses the most impactful visual effect.
Sketch I:
When I visualized the radial tree, for a 19-branch and 6-layer tree, the space is too small for the next 3D visualization.
So I decided to generate separate trees for each genre.
From above, it's easy to see the distribution for main genre and subgenres.
Final Result
Every pyramid represents a movie, lying at its genre path. The white label shows its title. The height of pyramid is its ranking and the size of bottom shows its budget. Also Pyramids in red indicate that this movie doesn't make any profit, but lose money instead.
The texts below is its tagline and keywords. Those words with high frequency have larger text size. We can even tell the main theme for this genre.
I also add UI -toggle button group. It has two modes: single-genre mode and multiple-genres mode. Under single-genre mode, it only allows to show one genre tree at one time. Under multiple-genres mode, genre trees can be shown altogether.
However, the more trees, the heavier computation. The rendering will be super slow and make you impossible to navigate the movie city.
- 3D data visualization based on genres of movies
Dataset
I use the dataset from TMDB(website same as IMDB but it provides open API to access to its database), which contains basic information of 4804 movies from 1930s to 2010s. The raw dataset that I pull down from TMDB API looks like this:
While processing nested json files within "genre" column, I found out that almost 90% movies are cross-genre. I thought it would be so much fun to visualize data based on such a complicated, nested and elegant feature. According to my statistical results, there are 19 single genres in total: "Foreign", "Documentary", "Western", "Mystery", "Family", "Animation", "Crime", "Comedy", "Action", "Adventure", "Drama", "Science Fiction", "Romance", "Horror", "Thriller", "Fantasy", "Music", "War", "History". For every movie, it has one main genre and zero or several subgenres. The best way to visualize the nested data is using the tree. A tree has 19 tree branches and every branch grow its own sub branches as sub genres.
A radial tree takes up the least area and expresses the most impactful visual effect.
Sketch I:
Final Result
The texts below is its tagline and keywords. Those words with high frequency have larger text size. We can even tell the main theme for this genre.
- Attachments
-
- Final_Project.zip
- (2.24 MiB) Downloaded 1837 times
Last edited by yankong on Thu Mar 15, 2018 1:55 pm, edited 2 times in total.
Re: 4 Final Project
3D Visualization of New York City Taxi Data
Overview of Project
For my final project, I decided to create an interactive visualization of New York City taxi data. Because I have never created a Javascript project before, I decided to use this project as an opportunity to do so.
The specifics of my visualization are(best read after running the code):
* The endpoint on the bottom plane is mapped to the pickup location of an entry of the dataset.
* The endpoint on the top plane is mapped to the dropoff.
* The time it took for the ride is mapped to the curveTightness. So in theory, longer rides should be more loopy. But, due to the way I chose the control points, it didn't create the contrast that I had hoped for.
* The payment is mapped to the color of each curve using the jet colormap. Meaning, blue is low, and red is high.
* Purpose of Top Map Button is so you can see where each datapoint's exact pickup location is, as it is somewhat blocked by top plane.
* By adjusting the sliders, you can filter the curves based on the payment and time interval you specify.
* Note that in order to update, the Max sliders need to be greater than their Min counterparts.
* Note that times and payments have a cutoff, so that I can utilize a larger range of the spectrum.
Data PreProcessing
The Taxi.ipynb notebook in the data folder will extract the nesscary columns, transform the time columns from seconds to minutes, and sets the cutoff for payment to 75 dollars and the time to 90 minutes.
Works in Process
First, to check that my world to plane map was working properly, I mapped a few locations that I knew.
Then I mapped the datapoints to lines, with time dictating the length of the line. This didn't turn out so great.
So instead, the made the length of the lines a fixed distance, and attached another plane on top.
Then, I added the functionality.(Well, at least the front end part)
Analysis
After finishing the project, I did some exploratory data analysis.
1. What rides are high in payment and time spent?
It turns out the ones coming out of JFK airport and into the heart of New York City.
2. Are there rides that are low in time, but high in payment?(Perhaps there is a location with a higher density of wealthy and generous patrons)
No, I guess not. The rides looked fairly random.
Comments
Although I had to spend more time debugging little errors due to the dyanmicaly typed nature of Javascrpt, I found that I didn't need to use as much print statements to get the state of variables, as I could simply open the console in the browser.
* But that said, this REPL does not work with the p5 manager http server for some reason. But, I have to use this so that the coloring of the lines would show.
The `texture()` function in p5js cannot be contained in a `push()` and `pop()`. The implications of this is that p5js would try to apply the texture to all the other geometric objects, such as the curves. Now, clearly this is ridiculous, but either p5js or Javascript is safely failing, and instead of throwing an error, the program will just not show the lines.
The easyCam constructor does not work with inputing the state. Same for its `pushResetState` method. I had to bypass by finding the name of the camera's reset state property, and manually setting that myself.
Apparently p5js does not allow pictures as background in WEBGL mode
Future Work
I had also wanted to include a filter for location, the solution I initally thought of was rather inelegant. It involved the used of 3 sliders for x,y, and radius. A better solution would be for the user to open up a new canvas that is 2D, with the map on it. This canvas will not use the easycam library, so this allows me to use the mouseHold callback. The user can now hold and drag a circle onto their desired location on the map, and use the mouseWheel to increase or decrease the size of the circle.
Overview of Project
For my final project, I decided to create an interactive visualization of New York City taxi data. Because I have never created a Javascript project before, I decided to use this project as an opportunity to do so.
The specifics of my visualization are(best read after running the code):
* The endpoint on the bottom plane is mapped to the pickup location of an entry of the dataset.
* The endpoint on the top plane is mapped to the dropoff.
* The time it took for the ride is mapped to the curveTightness. So in theory, longer rides should be more loopy. But, due to the way I chose the control points, it didn't create the contrast that I had hoped for.
* The payment is mapped to the color of each curve using the jet colormap. Meaning, blue is low, and red is high.
* Purpose of Top Map Button is so you can see where each datapoint's exact pickup location is, as it is somewhat blocked by top plane.
* By adjusting the sliders, you can filter the curves based on the payment and time interval you specify.
* Note that in order to update, the Max sliders need to be greater than their Min counterparts.
* Note that times and payments have a cutoff, so that I can utilize a larger range of the spectrum.
Data PreProcessing
The Taxi.ipynb notebook in the data folder will extract the nesscary columns, transform the time columns from seconds to minutes, and sets the cutoff for payment to 75 dollars and the time to 90 minutes.
Works in Process
Analysis
1. What rides are high in payment and time spent?
It turns out the ones coming out of JFK airport and into the heart of New York City.
2. Are there rides that are low in time, but high in payment?(Perhaps there is a location with a higher density of wealthy and generous patrons)
No, I guess not. The rides looked fairly random.
Comments
Although I had to spend more time debugging little errors due to the dyanmicaly typed nature of Javascrpt, I found that I didn't need to use as much print statements to get the state of variables, as I could simply open the console in the browser.
* But that said, this REPL does not work with the p5 manager http server for some reason. But, I have to use this so that the coloring of the lines would show.
The `texture()` function in p5js cannot be contained in a `push()` and `pop()`. The implications of this is that p5js would try to apply the texture to all the other geometric objects, such as the curves. Now, clearly this is ridiculous, but either p5js or Javascript is safely failing, and instead of throwing an error, the program will just not show the lines.
The easyCam constructor does not work with inputing the state. Same for its `pushResetState` method. I had to bypass by finding the name of the camera's reset state property, and manually setting that myself.
Apparently p5js does not allow pictures as background in WEBGL mode
Future Work
I had also wanted to include a filter for location, the solution I initally thought of was rather inelegant. It involved the used of 3 sliders for x,y, and radius. A better solution would be for the user to open up a new canvas that is 2D, with the map on it. This canvas will not use the easycam library, so this allows me to use the mouseHold callback. The user can now hold and drag a circle onto their desired location on the map, and use the mouseWheel to increase or decrease the size of the circle.
- Attachments
-
- P5_Projects.zip
- (5.65 MiB) Downloaded 1766 times
Last edited by bensonli on Thu Mar 15, 2018 1:57 pm, edited 2 times in total.
Re: 4 Final Project
Description:
I used the same data from the last assignment which contained the number of checkout time for ten categories books in ten years. The aim for the final project is to make visualization more clear that people can get information from the plot at first peek. The basic shape was not changed but the arrangement became different. Since there were exactly ten years and ten categories, I divided a circle into ten parts and made ten years data along the direction of split lines. Compared to the last assignment, this project showed clearer comparison between each month in same year. However, the trade-off was that user could not make comparison between different years. As a result, I add a feature for user to check the data in specific month. I designed two text field. If user only enter one month, sectoral cylinders would show above the center plane. If user typed in another month, the other sectoral cylinders would show in opposite direction. *The height and size do not represent the true number of original data due to the high ratio between the maximum and the minimum.
Inspiration:
The original concept was from the travel website.
However, I did not find suitable data for this shape. Moreover, the curve shape in 3D was hard to implement. Finally, it became more like a satellite.
Final Results:
The scaling methods for the height of cylinder and the size of triangle shape are different. Considering the contrast between different shapes in whole graph, it was not appropriate to use same method. However, users could still tell huge difference between categories. I would consider if it is necessary that the real number should be shown in the plot in the future. For the future work, I would like to turn this Processing version into p5.js or other javascript frame work(e.g d3.js deck.gl).
I used the same data from the last assignment which contained the number of checkout time for ten categories books in ten years. The aim for the final project is to make visualization more clear that people can get information from the plot at first peek. The basic shape was not changed but the arrangement became different. Since there were exactly ten years and ten categories, I divided a circle into ten parts and made ten years data along the direction of split lines. Compared to the last assignment, this project showed clearer comparison between each month in same year. However, the trade-off was that user could not make comparison between different years. As a result, I add a feature for user to check the data in specific month. I designed two text field. If user only enter one month, sectoral cylinders would show above the center plane. If user typed in another month, the other sectoral cylinders would show in opposite direction. *The height and size do not represent the true number of original data due to the high ratio between the maximum and the minimum.
Inspiration:
The original concept was from the travel website.
- Attachments
-
- Final_category_visualization.zip
- (170.34 KiB) Downloaded 1733 times
Last edited by mingyulin on Thu Mar 15, 2018 3:14 pm, edited 1 time in total.
-
christinalast
- Posts: 7
- Joined: Fri Jan 19, 2018 11:15 am
Re: 4 Final Project
Spatialising UCSB Research
To View in PDF: As a researcher, how would you go about finding work similar to your own? Measures of similarity could include research done in similar regions of the world, research by similar departments and scholars, research with topical correspondence, or research that co-occurred at the same temporality, reflecting contextual change. Determining these measures of similarity from a digital text collection requires mining document metadata. This project experiments with mapping from non-spatial tabular meta-data to spatialisations.
Spatial information provides guidance for the ways in which people, places and topics can be meaningfully displayed and analysed. Spatialization embeds documents into a metaphorical space where documents in closer proximity can be perceived as similar. Different conceptualizations of similarity, such as geographic and topical, lend themselves to analysis through different spatializations with varying measures of distance. By spatializing information, researchers can compute on collections of research documents, asking questions like “Where in the world is the density of my domain’s research the highest?”, “Which domain is the most spatially diverse? or “What other research shares the same spatial neighborhood as my domain?”
Analysis
For this assignment I am using the Alexandra Digital Research Library data. I scraped the ADRL UCSB Electronic Theses and Dissertations (N=1731) for the corresponding fields; Title, Year, Author, Degree Grantor, Supervisor, Description, Language, and wrote to csv. To select and group by department I ran the following query.
To identify any locations specific to the thesis or dissertation I pushed the results through a geoparser which compared the word strings to individual place names in Gazeteers. To do this I selected gazeteers at multiple levels of geography and parsed the strings through each, to extract place names from multiple place scales. The gazetteers downloaded were (GeoNames, ADL Gazetteer, U.S. Census, Wikipedia) to cover the potential range of current, historic and informal place names which may be included in the research titles and abstracts.
The geoparsed results are as follows:
- California cities where population > 50,000 as of 2004
o 170 cities: 98/1730 matches
- California cities (all) as of 2010
o 482 cities: 134/1730 matches
- California counties (all)
o 57 counties: 131/1730 matches
- CA urban areas (all)
o 155 urban areas: 99/1730 matches
- U.S. cities (major by population, 2014)
o 297 cities: 128/1730 matches
- U.S. places (Census)
o 29,576 places: 1298/1730 matches
- U.S. counties (Census)
o 3,219 counties: 12/1730 matches
- U.S. urban areas (Census)
o 3,600 urban areas: 595/1730 matches
- U.S. states
o 50 states: 176/1730 matches (cleaned to 166)
- Largest world cities
o 237 cities: 261/1730 matches
- Country names
o 203 countries: 277/1730 matches
This method underperformed in some categories, and because of this I tried implementing a machine learning algorithm Stanford’s Name Entity Recognition, which identifies places, organisations and names within text strings. The output was too difficult to clean in a short space of time so I kept this methodology.
The geoparsed results were read into R and geocoded using the following code which returns the latitude and longitude of the placename.
This data now has the correct information to geographically locate all the thesis and dissertations on to locations on earth. My strategy is inspired by the metaphor of global networks attributing cultures traditions and histories to different locales, and how researchers travel to investigate these cultural geographies and transfer those resources and knowledge to Santa Barbara. I aim to represent these flows of information from locations to UCSB within my visualisation.
Visualisation
This interactive 3D data visualization examines the relationship between different departments at UCSB and the geographic nature of their research. The result situates scientific research at UCSB in more powerful ways than library shelves, supporting multiple paradigms of data discovery. More broadly, this project allows me to generate verbal, written, and visual communication methods, with a particular emphasis on framing relationships, visual storytelling, and information design. Such spatializations will convey how scientific research topics are related through similarity (by department type and proximity).
Final Visuals
Interaction
Interactivity was introduced into this model, and each time a department is hovered over in the legend, only those links from that department are shown. This helps the user identify which departments are more ‘spatialised’ than others. As well as this, when the user has selected the department, the titles of the theses or dissertations associated with the geographic placements will be shown. Each of these items has a number in parenthesise provided, which reflects the number of places associated with that department or that thesis. As evident in the visualisation, some theses cover more than one location, which makes for rich geographical history of research at UCSB.
Lineage of Visual
To View in PDF: As a researcher, how would you go about finding work similar to your own? Measures of similarity could include research done in similar regions of the world, research by similar departments and scholars, research with topical correspondence, or research that co-occurred at the same temporality, reflecting contextual change. Determining these measures of similarity from a digital text collection requires mining document metadata. This project experiments with mapping from non-spatial tabular meta-data to spatialisations.
Spatial information provides guidance for the ways in which people, places and topics can be meaningfully displayed and analysed. Spatialization embeds documents into a metaphorical space where documents in closer proximity can be perceived as similar. Different conceptualizations of similarity, such as geographic and topical, lend themselves to analysis through different spatializations with varying measures of distance. By spatializing information, researchers can compute on collections of research documents, asking questions like “Where in the world is the density of my domain’s research the highest?”, “Which domain is the most spatially diverse? or “What other research shares the same spatial neighborhood as my domain?”
- Inspiration
- Initial ideas
For this assignment I am using the Alexandra Digital Research Library data. I scraped the ADRL UCSB Electronic Theses and Dissertations (N=1731) for the corresponding fields; Title, Year, Author, Degree Grantor, Supervisor, Description, Language, and wrote to csv. To select and group by department I ran the following query.
Code: Select all
# summarize publication ids by department
# select all publications from departments with over 50 publications
"degree_gra" = 'University of California, Santa Barbara. Electrical and computer engineering' OR
"degree_gra" = 'University of California, Santa Barbara. Electrical and Computer Engineering' OR
"degree_gra" = 'University of California, Santa Barbara. Materials' OR"degree_gra" = 'University of California, Santa Barbara. Chemistry' OR
"degree_gra" = 'University of California, Santa Barbara. Education' OR
"degree_gra" = 'University of California, Santa Barbara. Education - Gevirtz Graduate School' OR
"degree_gra" = 'University of California, Santa Barbara. Physics' OR
"degree_gra" = 'University of California, Santa Barbara. Computer Science' OR
"degree_gra" = 'University of California, Santa Barbara. Sociology' OR
"degree_gra" = 'University of California, Santa Barbara. Chemical Engineering' OR
"degree_gra" = 'University of California, Santa Barbara. History' OR
"degree_gra" = 'University of California, Santa Barbara. Psychology' OR
"degree_gra" = 'University of California, Santa Barbara. Geography' OR
"degree_gra" = 'University of California, Santa Barbara. Mechanical Engineering'
Code: Select all
import csv
import time
#import tab-delimited keywords file
f = open('gazetteers/us-places-clean.txt','r')
#gazetteer = f.read().lower().split("\r")
citylist = f.read().strip().split("\r")
f.close()
print(citylist[0:5])
gazetteer = []
for word in citylist:
word = word.rstrip()
gazetteer.append(word)
print(gazetteer[0:10])
theses = []
fullRow = []
with open('adrl.csv') as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
#the full row for each entry, which will be used to recreate the improved CSV file in a moment
fullRow.append((row['key'], row['title'], row['description']))
#the column we want to parse for our keywords
#row = row['description'].lower()
row = row['description']
theses.append(row)
#NEW! a flag used to keep track of which row is being printed to the CSV file
counter = 0
#NEW! use the current date and time to create a unique output filename
timestr = time.strftime("%Y-%m-%d-(%H-%M-%S)")
filename = 'output-' + str(timestr) + '.csv'
#NEW! Open the new output CSV file to append ('a') rows one at a time.
with open(filename, 'a') as csvfile:
#NEW! define the column headers and write them to the new file
fieldnames = ['key', 'title', 'description', 'place']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
#NEW! define the output for each row and then print to the output csv file
writer = csv.writer(csvfile)
#OLD! this is the same as before, for currentRow in fullRow:
# for texts in allTexts:
for thesis in theses:
matches = 0
storedMatches = []
#for each entry:
#allWords = entry.split(' ')
#for words in texts:
#remove punctuation that will interfere with matching
# words = words.replace(',', '')
# words = words.replace('.', '')
# words = words.replace(';', '')
#if a keyword match is found, store the result.
for place in gazetteer:
if place in thesis:
if place in storedMatches:
continue
else:
storedMatches.append(place)
# print(place)
matches += 1
#CHANGED! send any matches to a new row of the csv file.
if matches == 0:
newRow = fullRow[counter]
else:
matchTuple = tuple(storedMatches)
newRow = fullRow[counter] + matchTuple
#NEW! write the result of each row to the csv file
writer.writerows([newRow])
counter += 1- California cities where population > 50,000 as of 2004
o 170 cities: 98/1730 matches
- California cities (all) as of 2010
o 482 cities: 134/1730 matches
- California counties (all)
o 57 counties: 131/1730 matches
- CA urban areas (all)
o 155 urban areas: 99/1730 matches
- U.S. cities (major by population, 2014)
o 297 cities: 128/1730 matches
- U.S. places (Census)
o 29,576 places: 1298/1730 matches
- U.S. counties (Census)
o 3,219 counties: 12/1730 matches
- U.S. urban areas (Census)
o 3,600 urban areas: 595/1730 matches
- U.S. states
o 50 states: 176/1730 matches (cleaned to 166)
- Largest world cities
o 237 cities: 261/1730 matches
- Country names
o 203 countries: 277/1730 matches
This method underperformed in some categories, and because of this I tried implementing a machine learning algorithm Stanford’s Name Entity Recognition, which identifies places, organisations and names within text strings. The output was too difficult to clean in a short space of time so I kept this methodology.
The geoparsed results were read into R and geocoded using the following code which returns the latitude and longitude of the placename.
Code: Select all
#load ggmap
library(ggplot2)
library(ggmap)
#Read in the CSV and store it in a variable
origAddress <- read.csv("adrl.csv", stringsAsFactors = FALSE)
#initialise the dataframe
geocoded_1 <- data.frame(stringsAsFactors = FALSE)
#Loop through the addresses to get the latitude and longitude of each address and add it to the
#origAddress data frame in the new columns lat and long
for(i in 1:nrow(origAddress)){
result <- geocode(origAddress $place[i], output = "latlon", source = "google")
origAddress$lon[i] = as.numeric(result[1])
origAddress$lat[i] = as.numeric(result[2])
}
#write csv file to working directory containing origAddres
write.csv(origAddress, "fullListGeocoded.csv", row.names = FALSE)
Visualisation
This interactive 3D data visualization examines the relationship between different departments at UCSB and the geographic nature of their research. The result situates scientific research at UCSB in more powerful ways than library shelves, supporting multiple paradigms of data discovery. More broadly, this project allows me to generate verbal, written, and visual communication methods, with a particular emphasis on framing relationships, visual storytelling, and information design. Such spatializations will convey how scientific research topics are related through similarity (by department type and proximity).
Final Visuals
- Rendering all links
Interactivity was introduced into this model, and each time a department is hovered over in the legend, only those links from that department are shown. This helps the user identify which departments are more ‘spatialised’ than others. As well as this, when the user has selected the department, the titles of the theses or dissertations associated with the geographic placements will be shown. Each of these items has a number in parenthesise provided, which reflects the number of places associated with that department or that thesis. As evident in the visualisation, some theses cover more than one location, which makes for rich geographical history of research at UCSB.
Lineage of Visual
- Rendering individual links for Department
- Rendering individual links for Thesis title
- Attachments
-
- Spatialised_research_3D.zip
- (22.24 MiB) Downloaded 1734 times
Re: 4 Final Project
Top Wildlife Buyers and Sellers Worldwide in 2016
Dataset Analysis
The dataset I chose to visualize come from CITES, The Convention on International Trade in Endangered Species.
Almost every member nation in the UN participates the CITES. Members are obligated to report on roughly 5000 animal species and 29000 plant species brought into or exported out of their countries, and to honor limitations placed on the international trade of these species.
This dataset includes all legal species imports and exports carried out in 2016 and reported to CITES, over 67,000 records in total.
I start off with some Python preprocessing, to better understand the structure and metrics of this dataset. Here we see it contains 16 columns, which includes taxonomy, importer / exporter, quantity of each trade, and more.
Because the dataset contains many very detailed metrics, I found it is best to represent the trades based on importer and exporters, as they provide the most intuitive information of who are the major wildlife traders in the world. Since every trade records provides the info on both parties, we can also find out the trading status between all the countries, here I selected the top 10 importers and top 10 exporters (14 in total) to demonstrate.
Visualization Method
For the visualization, I used an algorithms called the flocking simulation which are often used in computer graphics to mimic the flock of birds, to represent each trade as a boat that delivers from the exporter to the importer. All the agents, or boats in this system are aware of it's surroundings, each of them will find their way to the destination and avoid running into each other, align in a group and move together by constantly calculating its neighbors' speed and direction.
Shaders are used to speed-up the rendering. All the calculation of agents are real time and lifelike. As well as the dataset, although I used Pandas with Python to understand the data, all the data extraction and calculation are done in Processing, upon the original raw data. The system will create all the boats by matching information from two hash-tables that are created at the start of the demo, one for trade and one for the traders. So this gives me the ability to show more types of information with minimal changes to the code.
Dataset Analysis
The dataset I chose to visualize come from CITES, The Convention on International Trade in Endangered Species.
Almost every member nation in the UN participates the CITES. Members are obligated to report on roughly 5000 animal species and 29000 plant species brought into or exported out of their countries, and to honor limitations placed on the international trade of these species.
This dataset includes all legal species imports and exports carried out in 2016 and reported to CITES, over 67,000 records in total.
Visualization Method
- Attachments
-
- wildlife_trade_boids.zip
- (550.42 KiB) Downloaded 1732 times
Last edited by chengyuan on Thu Mar 15, 2018 2:40 pm, edited 3 times in total.
Re: 4 Final Project
The Pursuit of Happiness
-100,000 happy moments from the happyDB
Introduction:
Happiness is not a uniform state that can be switched on and off on demand. Instead, it is a state or set of states that can be triggered by a rich tapestry of conditions and permutations of them. And yet there has been relatively little work that teases apart the nature of these conditions and how they arise.
What makes us happy, and what sustains this happiness over time? A huge database is making it possible to discern the answer at last.
https://rit-public.github.io/HappyDB/
By asking crowd workers the question: what made you happy in the past 24 hours (or alternatively, the past 3 months)?
Here are some of the happy moments:
1. My son gave me a big hug in the morning when I woke him up.
2. I finally managed to make 40 pushups.
3. I had dinner with my husband.
The Happy Word Cloud
The words “work” and “friend” appear most prominently in HappyDB; mentions of “wife” and “husband” occur about equally, and so do “son” and “daughter”. However, “girlfriend” occurs more often than “boyfriend” (1960 vs. 1252 times), “night” appears more often than “morning” (3391 vs. 2736 times), and “dog” occur much more often than “cat” (2160 vs. 988 times).
Design Concept:
Since the dataset is divided into seven categories: Achievement, Affection, Bonding, Enjoy the moment, Exercise, Leisure, Nature.
Seven is a very interesting number to present. The ancient Greeks believed that there were four elements that everything in nature was made up of: earth, water, air, and fire. Family is one unit of society, which consists of father, mother and child. Added up altogether, those are total seven elements. So I wanted to visualize those seven happy categories in my project.
The biggest difficulty I had for this project is the dataset CSV file is too big and always taking a very long time to load, so it is hard for me to debug or making new changes with the loading time so long for the dataset. So I down size the database to about total 10,000 entries just for demo purpose.
My Inspiration:
I got my inspiration from the toy that we all love to play when we were kids - pinwheel. It has seven colors and makes up a whole piece.
Work in Progress:
The Full dataset data:
When showing one category:
Conclusion:
Happiness is a diverse corpus with content that is emotionally rich and covers various topics
It is helpful that HappyDB can spur research of the topic of understanding happy moments and more generally, the expression of emotions in text.
We observe that the categories “food” and “entertainment” have higher percentage of coverage in 24 hour compared to the 3 months reflection period . Naturally, people are more likely to talk about a meal or a movie because these are more frequent daily events that are more likely to be remembered if they occurred recently. When people are asked to reflect on the past 3 months, they tend to remember events that are more prominent such as school, big achievements, and time spent with friends and family.
-100,000 happy moments from the happyDB
Introduction:
Happiness is not a uniform state that can be switched on and off on demand. Instead, it is a state or set of states that can be triggered by a rich tapestry of conditions and permutations of them. And yet there has been relatively little work that teases apart the nature of these conditions and how they arise.
What makes us happy, and what sustains this happiness over time? A huge database is making it possible to discern the answer at last.
https://rit-public.github.io/HappyDB/
By asking crowd workers the question: what made you happy in the past 24 hours (or alternatively, the past 3 months)?
Here are some of the happy moments:
1. My son gave me a big hug in the morning when I woke him up.
2. I finally managed to make 40 pushups.
3. I had dinner with my husband.
The Happy Word Cloud
Design Concept:
Since the dataset is divided into seven categories: Achievement, Affection, Bonding, Enjoy the moment, Exercise, Leisure, Nature.
The biggest difficulty I had for this project is the dataset CSV file is too big and always taking a very long time to load, so it is hard for me to debug or making new changes with the loading time so long for the dataset. So I down size the database to about total 10,000 entries just for demo purpose.
My Inspiration:
I got my inspiration from the toy that we all love to play when we were kids - pinwheel. It has seven colors and makes up a whole piece.
Happiness is a diverse corpus with content that is emotionally rich and covers various topics
It is helpful that HappyDB can spur research of the topic of understanding happy moments and more generally, the expression of emotions in text.
We observe that the categories “food” and “entertainment” have higher percentage of coverage in 24 hour compared to the 3 months reflection period . Naturally, people are more likely to talk about a meal or a movie because these are more frequent daily events that are more likely to be remembered if they occurred recently. When people are asked to reflect on the past 3 months, they tend to remember events that are more prominent such as school, big achievements, and time spent with friends and family.
- Attachments
-
- sketch_3dVisualization.zip
- (6.8 MiB) Downloaded 1744 times
-
Last edited by aprilcai on Thu Mar 15, 2018 2:59 pm, edited 8 times in total.
Re: 4 Final Project
BeHAVE: Heatmap-based Multimodal Representation of Personal Behavioral Data
This final project is the extension of my ongoing research, BeHAVE (Behavioral data as Heatmap-based Audio-Visual Expression), a web-based multimodal data representation that visualizes and sonifies my phone use behavior about where and how long I use my phone. Through this multimodal representation, this project attempts to not only improve the perception and understanding of self-tracking data but also arouse aesthetic enjoyment.
Data Collection and Preprocessing
For obtaining phone use data, an active screen time tracking iPhone application ‘Moment(https://inthemoment.io)’ has been used since January 20, 2017. Basically, this app detects a phone pickup which means when and where a user turns on or off his/her phone screen and calculates the duration between them. The app exports all pickup data as a JSON format file that includes a daily using time in minutes, the number of pickups, a location, date, and duration in seconds of each pickup, and most used apps based on apps’ battery usage. The exported file size of a year of data was about 5.6 Mb including the records of total 11,367 pickups. By using Python in the Jupyter Notebook(https://jupyter.org/), this raw data was parsed and processed to change it into a GeoJSON format, which is a geographic data structure and is used in a map-based visualization. The minimum, maximum, mean, and standard deviation value of the phone use duration are 0.017, 283.667, 6.243, and 14.465 minutes, respectively.
GeoJSON data example. It shows one record of all pickups
Visualization
A conventional way in visualizing geographic data is to plot data on an interactive or static map. A geographic heatmap is a particular way to identify where data occurs and depict the density of data in areas or at points. In this regard, a heatmap visualization is an appropriate way to represent the behavioral data of the phone use including location and time information. Due to the fact that the data is also temporal records, a feature for exploring and unfolding data over time is the key point to not only show a context and story of data but also evoke more aesthetic enjoyment in both visualization and sonification.
Screenshots of an Initial Interface
Heatmap Visualization with MapBox
To plot GeoJSON data on an online map, MapBox GS JS (https://www.mapbox.com/mapbox-gl-js), which is a WebGL based JavaScript library for rendering interactive maps, is used. The coordinates information of GeoJSON data determines locations of circles on a map and the use duration of each pickup is mapped onto the radius and color of each circle. According to a zoom level, it reveals detailed data points or makes clusters of closest circles. Also, an hourly heatmap at the bottom of a map that shows how long I used my phone hourly is used to select a date range of data to be plotted.
Temporal Data Exploration
For data exploration, a time value of GeoJSON data is mainly used. And, it is necessary to transform a time range of data into a shorter range to reveal and perceive a set of long-term records. BeHAVE basically represents the data set of a day in 2 seconds and as a result, iterates the data of 365 days for about 12 minutes, but it is flexible to change it. To allow audiences to focus on instant data occurrence over time, a drawn circle fades out in a short period which is proportional to a use duration value. Also, it draws an opaque line which connects a location of the previously shown data with a location of data will be displayed next so that audiences can recognize the routes of data.
Data Sonification
The main issue of sonification in this project is how to reflect the temporal property of data in a short period. The use duration of each pickup can vary from one second to hours and it has to be transformed into the sound of a fraction of a second which is proportional to a seconds-per-day value; e.g., when it is 2 seconds per day, 1 minute is (1/60)/24×2 = 0.0013s (=1.3ms)and the maximum value 283 minutes is 383 ms. This means that it is appropriate to deal with sound on a microsound timescale in which an acoustic event occurs within a duration near the threshold of human auditory perception from one to a hundred milliseconds.
Gibberish for Web-based Sound Synthesis
To build a stand-alone web application, a JavaScript sound synthesis and scheduling library, Gibberish (https://github.com/gibber-cc/gibberish) is used as a sound engine. One of the unique features Gibberish has is an ability to process and synthesis sound one sample at a time. This per-sample basis processing enables sample-accurate timing. BeHAVE can benefit from this feature because it generates microacoustic events.
Parameter Mapping for Microsound Events
Inspired by granular synthesis, which is the most renowned microsound synthesis technique, the main idea for sonification is to control the amplitude envelope of a waveform according to a use duration value. BeHAVE uses Gibberish’s Synth instrument, which provides a single oscillator feeding a selectable filter, and it has envelope properties such as attack, decay, sustain, release (ADSR), and sustain level. Synth is connected to Freeverb for a reverberation effect so that it makes a sound with a longer envelope duration linger long. BeHAVE reflects a distance between the last and next locations in a frequency. This approach brings about a more dynamic change in terms of the pitch of sound because a small difference between locations can be a discernible frequency change.
User Interaction and GUI
BeHAVE has a GUI for controlling playback and exploring data on a map. An audience can play or pause the data exploration mode and control the position of a timeline scrollbar to jump into a certain date. Also, it is possible to toggle full-screen mode and decide whether to see the background map information or not. During the data exploration, an audience can zoom in and out or move the center location of a map with a mouse to look over the overall shape or detail of drawn lines.
Final Result
Future Work
Since it is still in the experimental phase, it has a potential to be improved in data representation. Visual composition and forms can be more abstract or generative to cause aesthetic variation. Also, changing color scheme according to time will make audiences perceive the time change intuitively. Compared to the original idea of granular synthesis that uses a bunch of sound grains, different mapping strategies can be applied to synthesize sound more interestingly.
This final project is the extension of my ongoing research, BeHAVE (Behavioral data as Heatmap-based Audio-Visual Expression), a web-based multimodal data representation that visualizes and sonifies my phone use behavior about where and how long I use my phone. Through this multimodal representation, this project attempts to not only improve the perception and understanding of self-tracking data but also arouse aesthetic enjoyment.
Data Collection and Preprocessing
For obtaining phone use data, an active screen time tracking iPhone application ‘Moment(https://inthemoment.io)’ has been used since January 20, 2017. Basically, this app detects a phone pickup which means when and where a user turns on or off his/her phone screen and calculates the duration between them. The app exports all pickup data as a JSON format file that includes a daily using time in minutes, the number of pickups, a location, date, and duration in seconds of each pickup, and most used apps based on apps’ battery usage. The exported file size of a year of data was about 5.6 Mb including the records of total 11,367 pickups. By using Python in the Jupyter Notebook(https://jupyter.org/), this raw data was parsed and processed to change it into a GeoJSON format, which is a geographic data structure and is used in a map-based visualization. The minimum, maximum, mean, and standard deviation value of the phone use duration are 0.017, 283.667, 6.243, and 14.465 minutes, respectively.
Code: Select all
{
"type": "FeatureCollection",
"features": [
{
"type": "Feature",
"properties": {
"lengthInMinutes": 0.15,
"time": 0.0020833333333333333,
"date": "2017-01-20T00:03:44-08:00"
},
"geometry": {
"type": "Point",
"coordinates": [
-119.87071185363754,
34.41795049805089
] }
},
... ]
}
Visualization
A conventional way in visualizing geographic data is to plot data on an interactive or static map. A geographic heatmap is a particular way to identify where data occurs and depict the density of data in areas or at points. In this regard, a heatmap visualization is an appropriate way to represent the behavioral data of the phone use including location and time information. Due to the fact that the data is also temporal records, a feature for exploring and unfolding data over time is the key point to not only show a context and story of data but also evoke more aesthetic enjoyment in both visualization and sonification.
Screenshots of an Initial Interface
To plot GeoJSON data on an online map, MapBox GS JS (https://www.mapbox.com/mapbox-gl-js), which is a WebGL based JavaScript library for rendering interactive maps, is used. The coordinates information of GeoJSON data determines locations of circles on a map and the use duration of each pickup is mapped onto the radius and color of each circle. According to a zoom level, it reveals detailed data points or makes clusters of closest circles. Also, an hourly heatmap at the bottom of a map that shows how long I used my phone hourly is used to select a date range of data to be plotted.
Temporal Data Exploration
Data Sonification
The main issue of sonification in this project is how to reflect the temporal property of data in a short period. The use duration of each pickup can vary from one second to hours and it has to be transformed into the sound of a fraction of a second which is proportional to a seconds-per-day value; e.g., when it is 2 seconds per day, 1 minute is (1/60)/24×2 = 0.0013s (=1.3ms)and the maximum value 283 minutes is 383 ms. This means that it is appropriate to deal with sound on a microsound timescale in which an acoustic event occurs within a duration near the threshold of human auditory perception from one to a hundred milliseconds.
Gibberish for Web-based Sound Synthesis
To build a stand-alone web application, a JavaScript sound synthesis and scheduling library, Gibberish (https://github.com/gibber-cc/gibberish) is used as a sound engine. One of the unique features Gibberish has is an ability to process and synthesis sound one sample at a time. This per-sample basis processing enables sample-accurate timing. BeHAVE can benefit from this feature because it generates microacoustic events.
Parameter Mapping for Microsound Events
Inspired by granular synthesis, which is the most renowned microsound synthesis technique, the main idea for sonification is to control the amplitude envelope of a waveform according to a use duration value. BeHAVE uses Gibberish’s Synth instrument, which provides a single oscillator feeding a selectable filter, and it has envelope properties such as attack, decay, sustain, release (ADSR), and sustain level. Synth is connected to Freeverb for a reverberation effect so that it makes a sound with a longer envelope duration linger long. BeHAVE reflects a distance between the last and next locations in a frequency. This approach brings about a more dynamic change in terms of the pitch of sound because a small difference between locations can be a discernible frequency change.
User Interaction and GUI
BeHAVE has a GUI for controlling playback and exploring data on a map. An audience can play or pause the data exploration mode and control the position of a timeline scrollbar to jump into a certain date. Also, it is possible to toggle full-screen mode and decide whether to see the background map information or not. During the data exploration, an audience can zoom in and out or move the center location of a map with a mouse to look over the overall shape or detail of drawn lines.
Final Result
Since it is still in the experimental phase, it has a potential to be improved in data representation. Visual composition and forms can be more abstract or generative to cause aesthetic variation. Also, changing color scheme according to time will make audiences perceive the time change intuitively. Compared to the original idea of granular synthesis that uses a bunch of sound grains, different mapping strategies can be applied to synthesize sound more interestingly.
Re: 4 Final Project
Visualization of global natural hazards (volcano, tsunami and earthquakes)
I'd like to visualize the global hazard events happens over the year. The data can be obtained from NOAA website: https://www.ngdc.noaa.gov/hazard/hazards.shtml. I can obtain the data for three major hazards: volcano, tsunami and earthquakes. For each hazards, I obtained a csv files contain all the information for that hazard. Each row of the csv file is a log related to one specific events. There are several important information related to one event, for example, the latitude, longitude of each events, the year that events happened. There are also some other interesting information related, for example, the magnitude of the earthquake/volcano/tsunami, in which country, and how many people died as the result. I download all three csv files containing the above information. There are over 6000 events of both earthquakes and tsunami, and about 800 events of volcanos. The time range of the hazards happens from 2000 BC to now.
Concept:
To develop the visualization, I'd like to map the location of the data to the earth sphere. This can be done by using latitude and longitude of given by the csv files. Initially I just mapped all the events happens over the earth sphere:
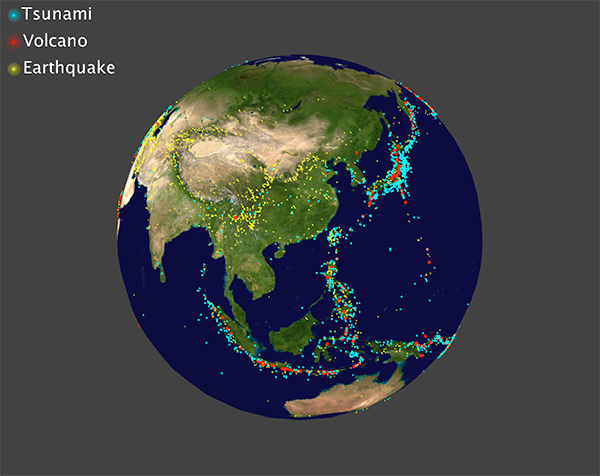
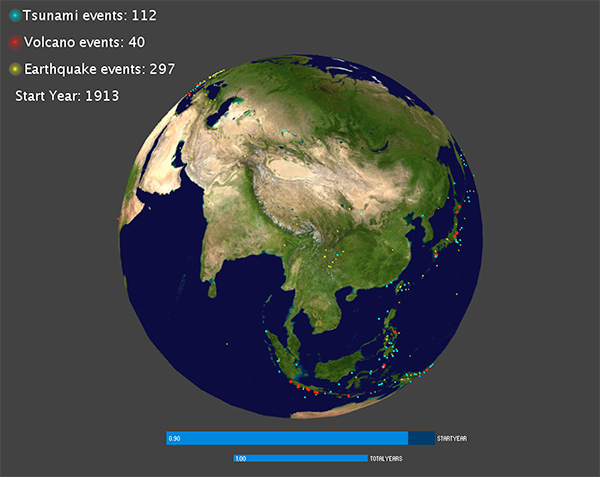
Then I noticed the events are too cluttered, so it may be better to display the events that happens at specific range of time. To do this, I added a slider for user to choose year with CP5, and another slider for user to choose how many events are displayed on the screen.
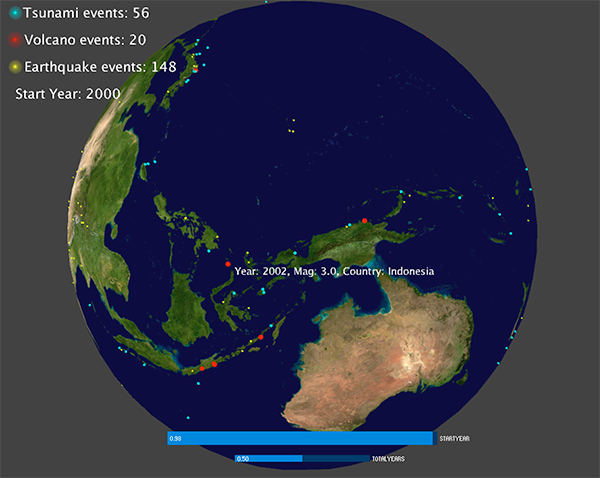
Since each events contains some interesting information, I'd like to display the information related to that events when the cursor is close to a specific events.
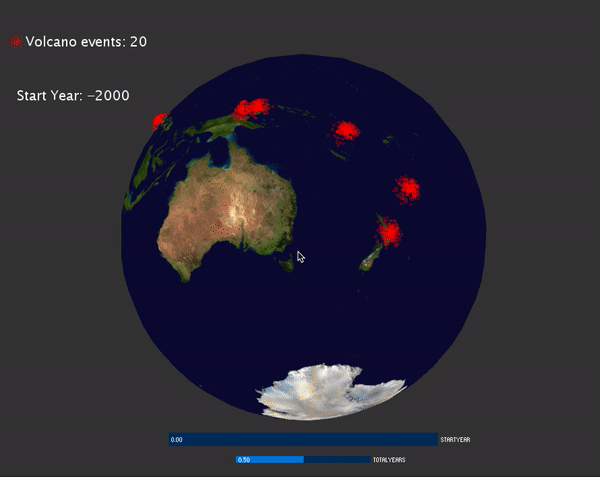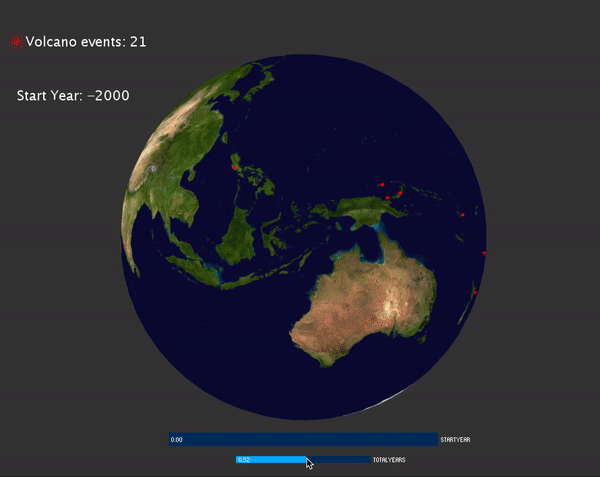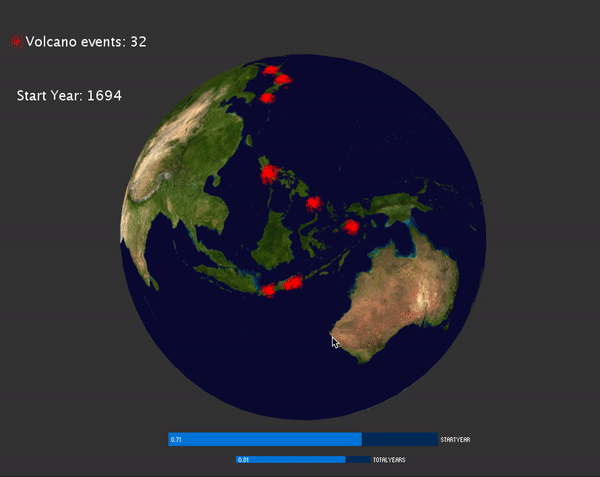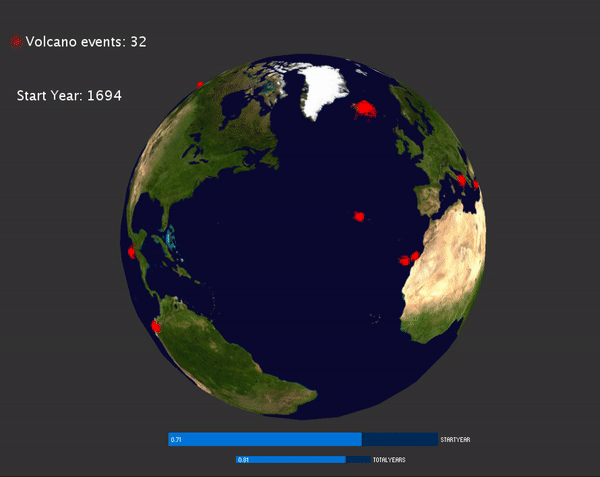
Next, to make the display of each events more interesting, I decided to use a line shader to display the tsunami and the earthquake events. And use particle system to display the volcano events.
VolcanoEvents:
Tsunami and Earthquake events:
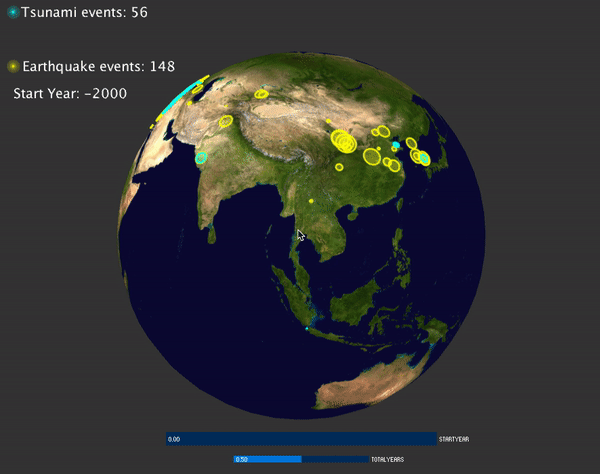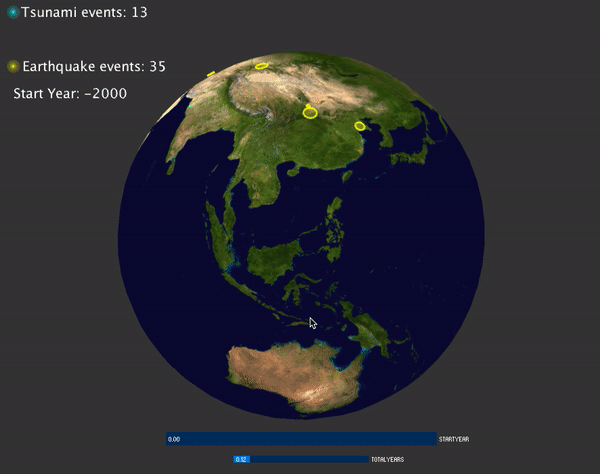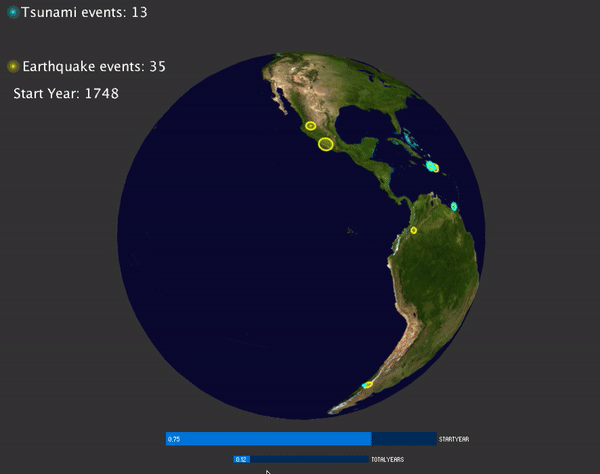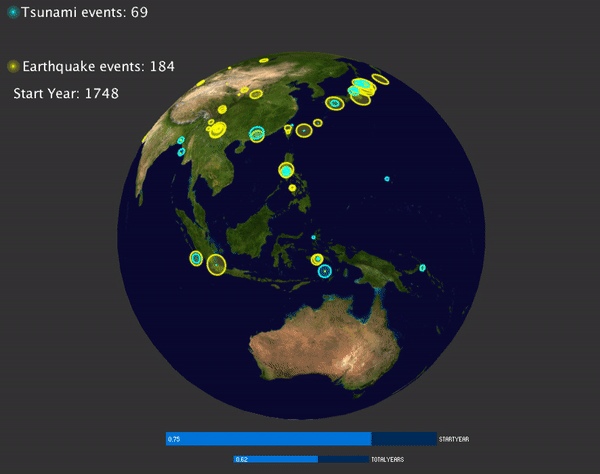
To visualize the magnitude of each events, for earthquake and tsunami events, the magnitude is mapped to the radius of the circle displayed. For volcano, the magnitude is mapped to the size of the particle system: the bigger the magnitude, more particles are emitted and the particles have larger velocity.
Some interaction tips are given at the beginning of the code.
I'd like to visualize the global hazard events happens over the year. The data can be obtained from NOAA website: https://www.ngdc.noaa.gov/hazard/hazards.shtml. I can obtain the data for three major hazards: volcano, tsunami and earthquakes. For each hazards, I obtained a csv files contain all the information for that hazard. Each row of the csv file is a log related to one specific events. There are several important information related to one event, for example, the latitude, longitude of each events, the year that events happened. There are also some other interesting information related, for example, the magnitude of the earthquake/volcano/tsunami, in which country, and how many people died as the result. I download all three csv files containing the above information. There are over 6000 events of both earthquakes and tsunami, and about 800 events of volcanos. The time range of the hazards happens from 2000 BC to now.
Concept:
To develop the visualization, I'd like to map the location of the data to the earth sphere. This can be done by using latitude and longitude of given by the csv files. Initially I just mapped all the events happens over the earth sphere:
Then I noticed the events are too cluttered, so it may be better to display the events that happens at specific range of time. To do this, I added a slider for user to choose year with CP5, and another slider for user to choose how many events are displayed on the screen.
Since each events contains some interesting information, I'd like to display the information related to that events when the cursor is close to a specific events.
Next, to make the display of each events more interesting, I decided to use a line shader to display the tsunami and the earthquake events. And use particle system to display the volcano events.
VolcanoEvents:
Tsunami and Earthquake events:
To visualize the magnitude of each events, for earthquake and tsunami events, the magnitude is mapped to the radius of the circle displayed. For volcano, the magnitude is mapped to the size of the particle system: the bigger the magnitude, more particles are emitted and the particles have larger velocity.
Some interaction tips are given at the beginning of the code.
- Attachments
-
- VisFinal.zip
- (17.28 MiB) Downloaded 1748 times
-
-
-
-
-
Last edited by qiaodong on Thu Mar 15, 2018 2:43 pm, edited 1 time in total.