What

Originally based on microphone recording (The "sound-field microphone"), but later available as synthesized technique for existing audio files.
Two perspectives
Recording/encoding
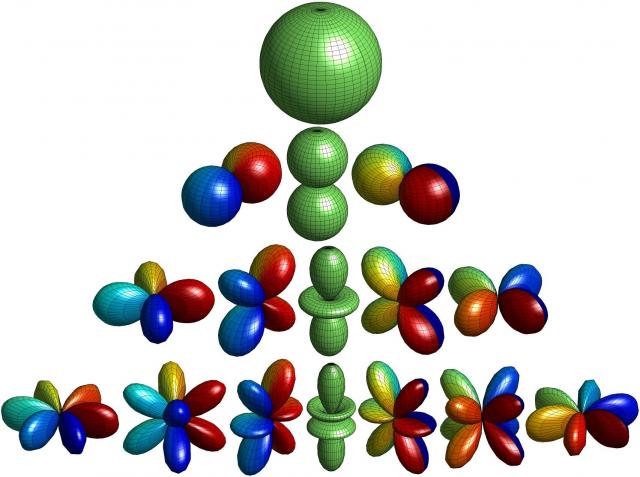
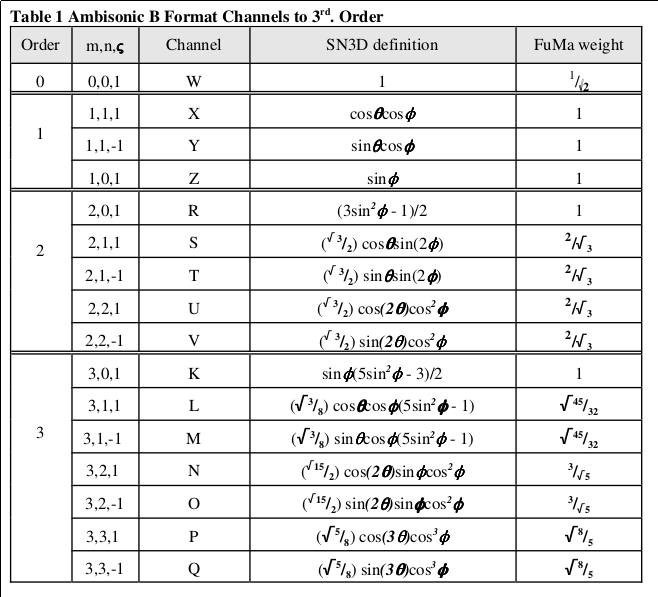
Formats
G-format
Once it became practical to transmit four channel or more, the obvious way to distribute ambisonic recordings is to use B-format. However, virtually no one has the necessary decoders to play such recordings (I believe that currently only Meridian sell equipment with that capability). Geoffrey Barton proposed that instead efforts should be concentrated for the time being on distributing speaker feeds, decoded for the currently popular 5.1 speaker layout. Michael teasingly referred to this as Geoffrey's format, which became G-format. In practice, the term G-format is now used in place of D-format for any set of speaker feeds.

How
Recording

An ideal soundfield microphone has infinitely small capsules whose response and direction match the shape of the spherical harmonics
Since this is impossible, through careful calibration and measurement, multiple capsules producing A-format can be converted into B-format.
Decoding
What ambisonics really is:
Gerzon has shown that the quality of localisation cues in the reproduced sound field corresponds to two objective metrics:
Many techniques to optimize and adjust decoding
Energy and velocity vectors
Described in Gerzon's article: Gerzon, M. A. (1992). General Metatheory of Auditory Localisation. In 92nd AES Convention.
The direction of each indicates the direction of the expected localization perception, while the magnitude indicates the quality of the localization. In "natural" hearing from a single source, the magnitude of each vector should be exactly 1, and the direction of the vectors is the direction to the source.
In first-order Ambisonics the zeroth-order component represents the sound pressure, and the three first-order components represent the acoustic pressure gradient from each direction.
However, it is not possible to get the first-order components correct except at a single point and not practical to get them correct at higher frequencies, where the wavelengths become smaller than the size of the human head
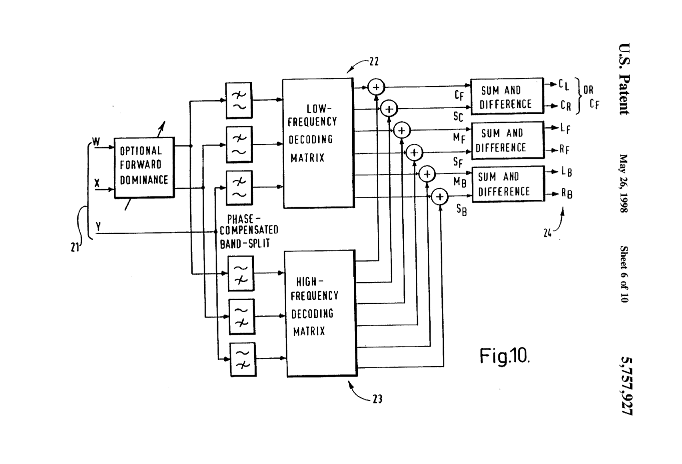
Vienna decoders
Decoder arranged to satisfy where the r.sub.v varies with azimuth, and, preferably, the directional gain pattern of the pressure signal P varies with frequency. Typically, for decoders having better front-stage than back-stage image stability, the back-sound gain divided by front-sound gain for the pressure signal will have a smaller value at low frequencies (for which r.sub.v typically equals 1) than at higher frequencies (for which typically r.sub.E is maximised with a greater value for front- stage sounds than for back-stage sounds).