

What?

How
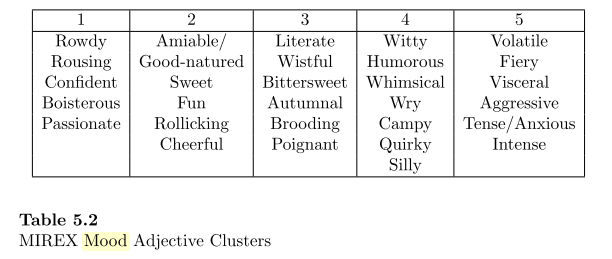
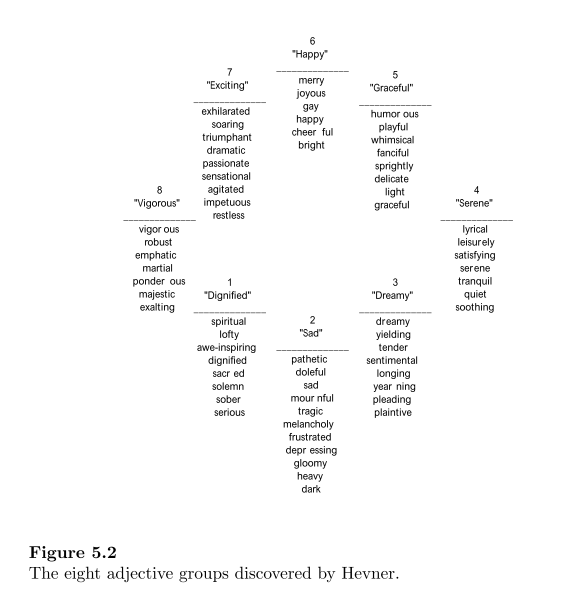
Mood and emotion classification from audio features

Li and Ogihara [47] used MFCC and short-term Fourier transform by way of Marsyas [81, 80], as well as statistics (the first three moments plus the mean of absolute value) calculated over subband coefficients obtained by applying the Daubechies Db8 wavelet filter [11] on the monaural signals (see Li and Ogihara [49]). On each axis, the accuracy of binary classification was in the 70% to 80% range for both labelers.
In 2007, Tzanetakis achieved the high- est correct classification (61.5%), using MFCC, spectral shape, centroid, and rolloff features with an SVM classifier [79]
The highest performing system in 2008 by Peeters demonstrated some improvement (63.7%) by introducing a much larger feature corpus including, MFCCs, Spectral Crest/Spectral Flat- ness, as well as a variety of chroma based measurements [61]. The system uses a Gaussian Mixture Model (GMM) approach to classification, but first em- ploys Inertia Ratio Maximization with Feature Space Projection (IRMFSP) to select the most informative 40 features for each task