Wk7 - Computational Camera
Wk7 - Computational Camera
From the Computational Photography resource link, select a topic of interest. Give a brief report, and describe how such a camera might advance your own artistic work
George Legrady
legrady@mat.ucsb.edu
legrady@mat.ucsb.edu
-
hcboydstun
- Posts: 9
- Joined: Mon Oct 01, 2012 3:14 pm
Re: Wk7 - Computational Camera
Within Harvard University’s Graphics, Vision and Interaction (GVI) department researchers Ayan Chakrabarti and Todd Zickler are experimenting with hyperspectural images. In order to fully understand the concept, I started by researching: What is spectral imaging?
Spectural imaging is ‘a branch of photography in which a complete spectrum is collected at every location at an image plane.’ In other words, a spectral image consists of various images of the same object, taken at differing parts of the light spectrum.

A hyperspectural image, like other spectural imaging, collects and analyzes data from across the electromagnetic spectrum. While the human eyes only see in three bands (red, green, and blue), which compose ‘visible light,’ hyperspectural imaging seeks to analyze data that is extended beyond this limited range of sight. Hence, hyperspectural imaging consists of a greater range of images than spectral images because hyperspectural images include infrared and thermal ranges, which again, cannot be seen by the naked eye.
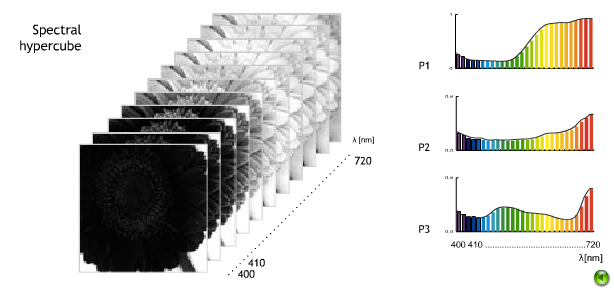
More so, ‘vision systems,’ which record hyperspectural data, can include a range of processing systems to built sensors. From these hyperspectural sensors researchers can analyze and categorize objects based on a ‘fingerprint,’ or spectural signatures, that they leave. This enables researchers to identify the objects based on the materials that make up the scanned object. (wikipedia) In the long term, hyperspectural imaging (along with its’ counter partner multispectral imaging, which measures reflected energy levels) would enable, for instance, NASA to extensively map and remotely sense the surface of the sun. As of today, hyperspectural data is used in military surveillance to produce thermal data in the dark and inter-mountain range typographic maps.
Thus, the aim of Harvard’s research is to use these ‘vision systems’ in order to create statistical models of natural, everyday hyperspectural images. In doing so, researchers hope further exploit the full benefits of hyperspectural data.
To collect the statistical data, Harvard researchers composed a database of fifty hyperspectural images, taken indoors and outdoors in the daylight, and a further twenty-five images under artificial light. Each image was filtered through a series of thirty-one narrow wavelength bands. In previous studies, the analysis of real- world spectra have been limited to collections of point samples, or in other words, hyperspectural sensors only collected a small sample of light and heat from specifically selected targets. Today, Chakrabarti and Zickler seek to consider that the spatial and hyperspectural dimensions jointly uncover additional structures. Thus, whereas most spectral images are represented as a ‘data cube’ or a small segmented cube of differing images, Harvard’s studies seek to provide a broader range of information by referencing the image as a whole, and overlapping each image to produce a wider scene of information.
In terms of my own interests, I researched hyperspectural imaging as a resource in restoring photographs. In recent years, much of the artwork I produced draws heavily from historical references in the past; whether that be using excepts of old library books, recovering old family photographs, or using pieces of old parchment paper. In using such pieces within my work, it is inevitable that run into the problem of time. Over time features on photographs, manuscripts, and other materials are often damaged, and thus, unusable in my work. Hyperspectural imaging, as is used by the US Library of the Congress, would allow me to look at documents at 'various magnification levels and in various types of light (raking, transmitted and different wavelengths.)' By doing so, I could capture some of these 'elusive features' that had been lost due to time, wear, or environmental factors.

http://gvi.seas.harvard.edu/paper/stati ... ral-images
http://en.wikipedia.org/wiki/Spectral_imaging
http://en.wikipedia.org/wiki/Hyperspectral_imaging
http://www.vision.uji.es/~essys/what.html
http://www.loc.gov/preservation/scienti ... aging.html
Spectural imaging is ‘a branch of photography in which a complete spectrum is collected at every location at an image plane.’ In other words, a spectral image consists of various images of the same object, taken at differing parts of the light spectrum.
A hyperspectural image, like other spectural imaging, collects and analyzes data from across the electromagnetic spectrum. While the human eyes only see in three bands (red, green, and blue), which compose ‘visible light,’ hyperspectural imaging seeks to analyze data that is extended beyond this limited range of sight. Hence, hyperspectural imaging consists of a greater range of images than spectral images because hyperspectural images include infrared and thermal ranges, which again, cannot be seen by the naked eye.
More so, ‘vision systems,’ which record hyperspectural data, can include a range of processing systems to built sensors. From these hyperspectural sensors researchers can analyze and categorize objects based on a ‘fingerprint,’ or spectural signatures, that they leave. This enables researchers to identify the objects based on the materials that make up the scanned object. (wikipedia) In the long term, hyperspectural imaging (along with its’ counter partner multispectral imaging, which measures reflected energy levels) would enable, for instance, NASA to extensively map and remotely sense the surface of the sun. As of today, hyperspectural data is used in military surveillance to produce thermal data in the dark and inter-mountain range typographic maps.
Thus, the aim of Harvard’s research is to use these ‘vision systems’ in order to create statistical models of natural, everyday hyperspectural images. In doing so, researchers hope further exploit the full benefits of hyperspectural data.
To collect the statistical data, Harvard researchers composed a database of fifty hyperspectural images, taken indoors and outdoors in the daylight, and a further twenty-five images under artificial light. Each image was filtered through a series of thirty-one narrow wavelength bands. In previous studies, the analysis of real- world spectra have been limited to collections of point samples, or in other words, hyperspectural sensors only collected a small sample of light and heat from specifically selected targets. Today, Chakrabarti and Zickler seek to consider that the spatial and hyperspectural dimensions jointly uncover additional structures. Thus, whereas most spectral images are represented as a ‘data cube’ or a small segmented cube of differing images, Harvard’s studies seek to provide a broader range of information by referencing the image as a whole, and overlapping each image to produce a wider scene of information.
In terms of my own interests, I researched hyperspectural imaging as a resource in restoring photographs. In recent years, much of the artwork I produced draws heavily from historical references in the past; whether that be using excepts of old library books, recovering old family photographs, or using pieces of old parchment paper. In using such pieces within my work, it is inevitable that run into the problem of time. Over time features on photographs, manuscripts, and other materials are often damaged, and thus, unusable in my work. Hyperspectural imaging, as is used by the US Library of the Congress, would allow me to look at documents at 'various magnification levels and in various types of light (raking, transmitted and different wavelengths.)' By doing so, I could capture some of these 'elusive features' that had been lost due to time, wear, or environmental factors.
http://gvi.seas.harvard.edu/paper/stati ... ral-images
http://en.wikipedia.org/wiki/Spectral_imaging
http://en.wikipedia.org/wiki/Hyperspectral_imaging
http://www.vision.uji.es/~essys/what.html
http://www.loc.gov/preservation/scienti ... aging.html
Re: Wk7 - Computational Camera
Christin Nolasco - Report on Computational Camera
Yoichi Sato's Lab's research on sensing human motions and detection-based systems is intriguing because it ties a great deal into the development of technology today with the ever-increasing popularity of technologies that respond to human interaction and incorporate detection technologies (i.e. tablets, iPhones/iPads, Androids, cameras, etc.).
One such device that the Sato Laboratory has researched is an augmented desk system that allows for two-handed drawing. Real-time finger tracking systems allow each hand to interact with the desk system. Gesture recognition even allows for some objects to be drawn by handwriting. In addition, each hand is assigned a different task. The right hand is used for drawing and manipulating objects. In comparison, the left hand is used to manipulate menus and assist the right hand in functions such as drawing or specifying objects.

Yoichi Sato's Lab is also looking into a way to model objects with transparent surfaces. I thought that this research was particularly interesting because the modeling of objects is very important in today's world because it allows for a greater understanding of that object. In order to create such a model, the surface orientations have to be detected through the examination of polarization in the reflection of the transparent object's surface and emission in visible and far-infrared wavelengths. The reflected wavelengths thus allow, or light, allow for a determination of where the transparent surface is at. Natural light is generally unpolarized, meaning it oscillates in all directions. But when it passes through a polarized material or reflected off a surface, the degree of oscillation is able to be obtained. Sato's Lab intends to create an apparatus that detects these wavelengths, or light, in order to determine the surface orientation. In order to achieve this, the object has to be illuminated from all directions in order to see the reflections of the entire object's surface. In addition, thermal radiation, which has some degrees of polarization, can be used as an infrared light to further examine transparent surface orientations.

Yoichi Sato's Lab's research on sensing human motions and detection-based systems is intriguing because it ties a great deal into the development of technology today with the ever-increasing popularity of technologies that respond to human interaction and incorporate detection technologies (i.e. tablets, iPhones/iPads, Androids, cameras, etc.).
One such device that the Sato Laboratory has researched is an augmented desk system that allows for two-handed drawing. Real-time finger tracking systems allow each hand to interact with the desk system. Gesture recognition even allows for some objects to be drawn by handwriting. In addition, each hand is assigned a different task. The right hand is used for drawing and manipulating objects. In comparison, the left hand is used to manipulate menus and assist the right hand in functions such as drawing or specifying objects.
Yoichi Sato's Lab is also looking into a way to model objects with transparent surfaces. I thought that this research was particularly interesting because the modeling of objects is very important in today's world because it allows for a greater understanding of that object. In order to create such a model, the surface orientations have to be detected through the examination of polarization in the reflection of the transparent object's surface and emission in visible and far-infrared wavelengths. The reflected wavelengths thus allow, or light, allow for a determination of where the transparent surface is at. Natural light is generally unpolarized, meaning it oscillates in all directions. But when it passes through a polarized material or reflected off a surface, the degree of oscillation is able to be obtained. Sato's Lab intends to create an apparatus that detects these wavelengths, or light, in order to determine the surface orientation. In order to achieve this, the object has to be illuminated from all directions in order to see the reflections of the entire object's surface. In addition, thermal radiation, which has some degrees of polarization, can be used as an infrared light to further examine transparent surface orientations.
Last edited by aleforae on Tue Nov 13, 2012 8:46 am, edited 2 times in total.
Wk7 - Computational Camera
Sydney Vande Guchte - A Spectral BSSRDF for Shading Human Skin
Computer Graphics, UCSD
People
Research Focus
CISA3
At the University of California San Diego researchers Craig Donner and Henrik Wann Jensen have created a "novel spectral shading model for human skin." They take into consideration both the uppermost layer and sublayer of skin to replicate the affect of light on human skin. To achieve the complex appearance of skin, they take into account the amount of oil, melanin, and hemoglobin. Melanin is composed of various polymers that range from yellow to dark brown and black. Pheomelanin is lighter melanin and eumelanin is darker melanin. Different concentrations allow for different pigmentations of skin and hair. Hemoglobin is responsible for carrying oxygen throughout the body.
These components enable custom wavelengths to be generated, which allow for the subsurface scattering within skin that create the simulation of African, Asian, and Caucasian skins. Subsurface scattering information is combined with Hanrahan and Krueger's Torrance- Sparrow BRDF to replicate light and oiliness. BRDF assumes light comes into and leaves the skin at a single point, making it unable to convey the softness and "color bleeding effects" characteristic to skin due to its translucency (Section 1). Skin scatters light not only because of its translucency but also due to changes in refraction relative to structures within the skin as well as collagen and elastin fibers.
Shading of the skin is determined by surface reflection due exclusively to oil, spectral scattering beneath the surface of skin due to light that passes through, and texture from an "albedo map," which accounts for the environment's lighting (Section 3).
Donnor and Jensen's work uses a 2 layer skin model that includes the epidermis, the upper layer, and the dermis, the sublayer. The total spectrum of the epidermis is a combination of the amount of melanin and the amount of eumelanin relative to the pheomelanin. The total spectral absorption of the dermis is the amount of hemoglobin (10-20% depending on location and skin type) and the blood oxygenation ratio between deoxygenated and oxygenated hemoglobin. The deeper skin of the dermis is less scattering than the epidermis and so the researchers have assumed its scattering as a constant coefficient; 50%. The epidermal's thickness is assumed as .25 mm with a constant refraction of 1.4 (Section 3.5). Spectral diffusion models are made for each layer, which are united to create a single skin profile.
Scattering is further altered by albedo texture, which accounts for details like freckles and splotches (Section 3.6). Reflected light highlights skin texture and therefore texture is achieved by removing different chromophore amounts from each pixel.
On a standard PC, researchers are able to generate skin tones and textures in less than 10 minutes! The parameters under consideration in its creation are "total melanin content, melanin type, hemoglobin content and surface oiliness" (Section 5). In their conclusion, researchers state that they hope to use the model to automatically recover parameters from real skin.
I have recently been experimenting with photoshop, so this program was pretty exciting to read about. This research would enable completely new possibilities for computer graphics and animation. The fact that they hope to one day be able to generate the parameters for any particular real skin is very interesting. Perhaps in future animations, human actors will no longer be necessary because they can be so easily created with the computer. Although I'm hardly good at working computer programs, if I were given the opportunity to use this research towards my own project, I'd propose recreating a movie in which all of the original actors are generated with Donner and Jensen's model.
http://graphics.ucsd.edu/papers/egsr200 ... 06skin.pdf
Computer Graphics, UCSD
People
Research Focus
CISA3
At the University of California San Diego researchers Craig Donner and Henrik Wann Jensen have created a "novel spectral shading model for human skin." They take into consideration both the uppermost layer and sublayer of skin to replicate the affect of light on human skin. To achieve the complex appearance of skin, they take into account the amount of oil, melanin, and hemoglobin. Melanin is composed of various polymers that range from yellow to dark brown and black. Pheomelanin is lighter melanin and eumelanin is darker melanin. Different concentrations allow for different pigmentations of skin and hair. Hemoglobin is responsible for carrying oxygen throughout the body.
Shading of the skin is determined by surface reflection due exclusively to oil, spectral scattering beneath the surface of skin due to light that passes through, and texture from an "albedo map," which accounts for the environment's lighting (Section 3).
Donnor and Jensen's work uses a 2 layer skin model that includes the epidermis, the upper layer, and the dermis, the sublayer. The total spectrum of the epidermis is a combination of the amount of melanin and the amount of eumelanin relative to the pheomelanin. The total spectral absorption of the dermis is the amount of hemoglobin (10-20% depending on location and skin type) and the blood oxygenation ratio between deoxygenated and oxygenated hemoglobin. The deeper skin of the dermis is less scattering than the epidermis and so the researchers have assumed its scattering as a constant coefficient; 50%. The epidermal's thickness is assumed as .25 mm with a constant refraction of 1.4 (Section 3.5). Spectral diffusion models are made for each layer, which are united to create a single skin profile.
On a standard PC, researchers are able to generate skin tones and textures in less than 10 minutes! The parameters under consideration in its creation are "total melanin content, melanin type, hemoglobin content and surface oiliness" (Section 5). In their conclusion, researchers state that they hope to use the model to automatically recover parameters from real skin.
Last edited by sydneyvg on Tue Nov 13, 2012 10:03 pm, edited 3 times in total.
Re: Wk7 - Computational Camera
Computer Depiction and Non-Photorealistic Rendering
by MIT CSAIL Computer Graphics Group
There is much study being done on the abilities of computer programming in creating new manners with which to create art. For example, the “Programmable Style for NPR Line Drawing” research being done by MIT students Stéphane Grabli, Emmanuel Turquin, Frédo Durand and François Sillion explores the ways in which computers can draw and create line-art.
Non-Photorealistic images created through computers are done so with a software that is limited and lacks flexibility. The research being done currently is done with the purpose of expanding the limitations of programming for computational line drawings. With the new programming, a greater variety of styles will be available as well as more choices within each individual style(for example, the amount or size of “brushstrokes”, etc.).
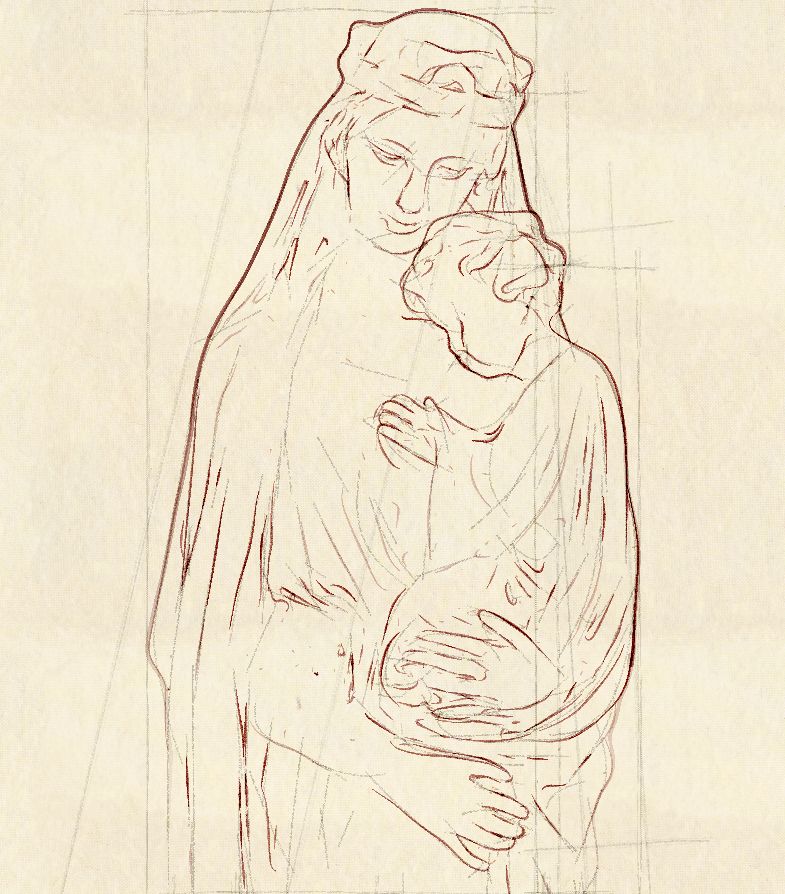
This is an image created computationally with the Maverick system.
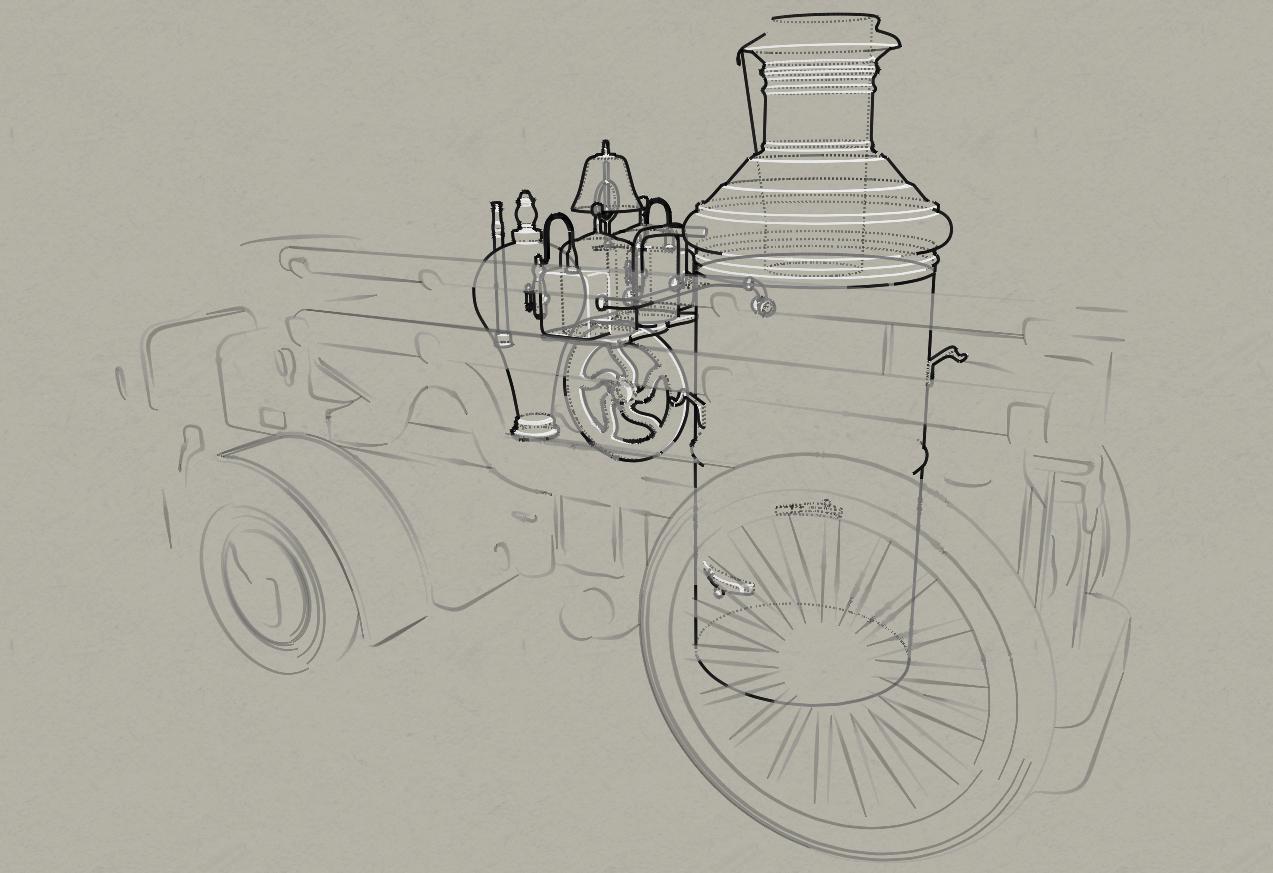
Here is another image of a computational line drawing.
It is obvious that the programming takes its inspiration from traditional freehand line drawing. This type of research, however, expands the circle of people whom can create good line images. In the past, only those with artistic talent and practice would be suitable for creating such an image, but with new programming, this will not always be the case.
In this way the new programming will be useful in animation in a large way. New styles of animation will be available in faster amounts of time than traditionally. Also, traditional fine arts will be changed in that artists(and others) can use the programming to create a wider range of good images, creating a more competitive image-producing community. On the project website for this research group, images and a gallery are available for viewing as well as a page dedicated to the actual programming involved in the project.
This is just one of many research topics within computational rendering, and along with all the other research happening, the way images are made and consumed is sure to change, yet again, shortly.
As an artist, I see this research as potential for another media. Technological advancement is sometimes seen as a threat; as a replacement of human talent by machines. However, new programming has in the past opened up new doors for artists of all types, and I am positive it will continue to do so.
by MIT CSAIL Computer Graphics Group
There is much study being done on the abilities of computer programming in creating new manners with which to create art. For example, the “Programmable Style for NPR Line Drawing” research being done by MIT students Stéphane Grabli, Emmanuel Turquin, Frédo Durand and François Sillion explores the ways in which computers can draw and create line-art.
Non-Photorealistic images created through computers are done so with a software that is limited and lacks flexibility. The research being done currently is done with the purpose of expanding the limitations of programming for computational line drawings. With the new programming, a greater variety of styles will be available as well as more choices within each individual style(for example, the amount or size of “brushstrokes”, etc.).
This is an image created computationally with the Maverick system.
Here is another image of a computational line drawing.
It is obvious that the programming takes its inspiration from traditional freehand line drawing. This type of research, however, expands the circle of people whom can create good line images. In the past, only those with artistic talent and practice would be suitable for creating such an image, but with new programming, this will not always be the case.
In this way the new programming will be useful in animation in a large way. New styles of animation will be available in faster amounts of time than traditionally. Also, traditional fine arts will be changed in that artists(and others) can use the programming to create a wider range of good images, creating a more competitive image-producing community. On the project website for this research group, images and a gallery are available for viewing as well as a page dedicated to the actual programming involved in the project.
This is just one of many research topics within computational rendering, and along with all the other research happening, the way images are made and consumed is sure to change, yet again, shortly.
As an artist, I see this research as potential for another media. Technological advancement is sometimes seen as a threat; as a replacement of human talent by machines. However, new programming has in the past opened up new doors for artists of all types, and I am positive it will continue to do so.
-
amandajackson
- Posts: 9
- Joined: Mon Oct 01, 2012 3:17 pm
Personalized Photograph Ranking and Selection System
Personalized Photograph Ranking and Selection System
Che-Hua Yeh, Yuan-Chen Ho, Brian A. Barsky, Ming Ouhyoung
University of California, Berkeley Computer Science Division and School of Optometry
With the recent and exponentially growing use of digital cameras for personal photography, users spend a lot of time browsing through their photos. Wouldn't it be great if there was a technology that catered to your personal preferences of "quality images" and discarded the unattractive images? To teach the computer system to adopt the personal preferences of the image user, training images are provided. The user separates the images in to two categories: preferred and not preferred. Based on these preferences of the training images, the computer analyzes and extracts the features that are most commonly preferred and applies them to future organization of images.
Rules of aesthetics, including photographic composition, are analyzed by the system in order to rank the images from professional to amateur. The images are also ranked according to texture, clarity, color harmonization, balance of intensity, and contrast. In addition to these compositional guidelines, the program considers the personal preferences of the user. These preferences are color, black and white ratio, face detection, and aspect ratio.
In regards to my own work, geography, this use of preference based, smart detection technology may be applied to remote sensing: both satellite imagery and more likely aerial photographs. Aerial photographs are obtained from a camera attached to an aerial platform, a plane. One area that is being photographed may have numerous images, all with a significant percentage of overlap and sidelap to ensure that the targeted area has been covered and there are objects which appear in multiple images for the effect of scale and regional identification. Remote sensing is a process that is used for a number of purposes. Military reconnaissance has been the most widely used application of remote sensing, however in more recent years there has been much use in the fields of environmental as well as urban management and research. This technology of preferences and image rankings would be a great tool in this field.

Lets look at environmental aspects for example:
If a geographer were interested in the population of tree species in a specific forrest area, they may use aerial photography to document the area and then identify the tree species through image interpretation. However, the process of image interpretation is a difficult one: you must not only be familiar with the technical aspects of photography including tone, texture, color, size, depth, etc., but you must also be familiar with the area that you are surveying (i.e. the trees and their image from above- tree crowns) By being able to identify the crown of the tree in association to one another, the researcher is able to map the differing tree populations in the forrest. So what is the problem? There isa very limited number of geographers that are trained with a high level of remote sensing and have the skills to perform such detailed work. The solution: use detection and preference technology such as the Personalized Photographic Ranking and Selection program researched at Berkeley to train computers to identify objects such a tree crowns.
Che-Hua Yeh, Yuan-Chen Ho, Brian A. Barsky, Ming Ouhyoung
University of California, Berkeley Computer Science Division and School of Optometry
With the recent and exponentially growing use of digital cameras for personal photography, users spend a lot of time browsing through their photos. Wouldn't it be great if there was a technology that catered to your personal preferences of "quality images" and discarded the unattractive images? To teach the computer system to adopt the personal preferences of the image user, training images are provided. The user separates the images in to two categories: preferred and not preferred. Based on these preferences of the training images, the computer analyzes and extracts the features that are most commonly preferred and applies them to future organization of images.
- system overview.
In regards to my own work, geography, this use of preference based, smart detection technology may be applied to remote sensing: both satellite imagery and more likely aerial photographs. Aerial photographs are obtained from a camera attached to an aerial platform, a plane. One area that is being photographed may have numerous images, all with a significant percentage of overlap and sidelap to ensure that the targeted area has been covered and there are objects which appear in multiple images for the effect of scale and regional identification. Remote sensing is a process that is used for a number of purposes. Military reconnaissance has been the most widely used application of remote sensing, however in more recent years there has been much use in the fields of environmental as well as urban management and research. This technology of preferences and image rankings would be a great tool in this field.
Lets look at environmental aspects for example:
If a geographer were interested in the population of tree species in a specific forrest area, they may use aerial photography to document the area and then identify the tree species through image interpretation. However, the process of image interpretation is a difficult one: you must not only be familiar with the technical aspects of photography including tone, texture, color, size, depth, etc., but you must also be familiar with the area that you are surveying (i.e. the trees and their image from above- tree crowns) By being able to identify the crown of the tree in association to one another, the researcher is able to map the differing tree populations in the forrest. So what is the problem? There isa very limited number of geographers that are trained with a high level of remote sensing and have the skills to perform such detailed work. The solution: use detection and preference technology such as the Personalized Photographic Ranking and Selection program researched at Berkeley to train computers to identify objects such a tree crowns.
Sketch Realizing
Di Wu and Qionghai Dai’s project Sketch Realizing is a rather clever and innovative way to render a sketch onto a life-like picture. With the use of a digital library a person can quickly sketch a face and certain steps are taken to grab certain features from different photographs and the face in the sketch is now life like.

In order for it to be successful in creating an image it needs a database with a large amount of pictures. With each picture certain facial pictures need to be located and outlined: the outline of the face, inner and outer boundaries of the lips, eyebrows, eyes and the nose all need to be outlined by hand. Once that is done the image is then systematically calculated to scale and rotate to be input into the database properly. Then tags/keywords need to be entered such as age and sex.
So within the search engine the user inputs a sketch and an photographical image is then rendered from the sketch. In order to get a similar looking face from sketch to image it’s important to add facial constraints such as the furrow from the eyebrows, the crease in a frown. Different regions of features are also necessary to include into the database as eyebrow and eye shapes, facial structure, lips and various other attributes are component features when making an image.

Face swapping can also be used to give a desired effect in a picture such as to make lips and eyes bigger, like a quick and easy way of using Photoshop.
One main reason this tool would be useful is identifying criminals from witness to witness. It will not be completely accurate but it can still be used for investigation purposes.
Now within the art world it can be used as an easier photo manipulation tool like photoshop but for those who are not able to grasp photoshop quickly enough. That’s one of the obvious choices but the Sketch Realizing can aid artists from beginners to advance to further understand facial construction, anatomy and racial anatomy within their own drawings. Storyboard, 3-D, concept artists and animators going for a realistic approach can create quick mock-ups to illustrate their characters. The time spent in drafts and concept art can be cut in half and reconstructions of the face can be done quickly. Timelines would be less of an issue. If the database and the technology could spread towards the rest of the body it can help artists immensely from once again anatomy or quickly doodling something out to see if the pose seems natural enough and not too stiff.
Sketch Realizing has the ability to help many in the artistic field as well as the forensic field or to plainly use as a photo manipulation tool like some app.
Sources:
http://media.au.tsinghua.edu.cn/wudi/Sk ... lizing.pdf
http://media.au.tsinghua.edu.cn/wudi.jsp

In order for it to be successful in creating an image it needs a database with a large amount of pictures. With each picture certain facial pictures need to be located and outlined: the outline of the face, inner and outer boundaries of the lips, eyebrows, eyes and the nose all need to be outlined by hand. Once that is done the image is then systematically calculated to scale and rotate to be input into the database properly. Then tags/keywords need to be entered such as age and sex.
So within the search engine the user inputs a sketch and an photographical image is then rendered from the sketch. In order to get a similar looking face from sketch to image it’s important to add facial constraints such as the furrow from the eyebrows, the crease in a frown. Different regions of features are also necessary to include into the database as eyebrow and eye shapes, facial structure, lips and various other attributes are component features when making an image.

Face swapping can also be used to give a desired effect in a picture such as to make lips and eyes bigger, like a quick and easy way of using Photoshop.
One main reason this tool would be useful is identifying criminals from witness to witness. It will not be completely accurate but it can still be used for investigation purposes.
Now within the art world it can be used as an easier photo manipulation tool like photoshop but for those who are not able to grasp photoshop quickly enough. That’s one of the obvious choices but the Sketch Realizing can aid artists from beginners to advance to further understand facial construction, anatomy and racial anatomy within their own drawings. Storyboard, 3-D, concept artists and animators going for a realistic approach can create quick mock-ups to illustrate their characters. The time spent in drafts and concept art can be cut in half and reconstructions of the face can be done quickly. Timelines would be less of an issue. If the database and the technology could spread towards the rest of the body it can help artists immensely from once again anatomy or quickly doodling something out to see if the pose seems natural enough and not too stiff.
Sketch Realizing has the ability to help many in the artistic field as well as the forensic field or to plainly use as a photo manipulation tool like some app.
Sources:
http://media.au.tsinghua.edu.cn/wudi/Sk ... lizing.pdf
http://media.au.tsinghua.edu.cn/wudi.jsp
Last edited by rosadiaz on Tue Nov 13, 2012 10:06 pm, edited 1 time in total.
-
kateedwards
- Posts: 17
- Joined: Mon Oct 01, 2012 3:15 pm
Re: Wk7 - Computational Camera
The IMAGER Computer Graphics Lab, part of the University of British Columbia, has published an article addressing the issues of color correction for tone mapping in digitally enhanced/manipulated images. The research team notes that while camera technologies attempt to account for “real-world” luminance and compensate for variety in contrast and exposure in order to achieve such an effect, the result is often a loss in color correctness. Their study focuses on the potential for color correction formulas through tone mapping which will create final images more closely resembling the original composition. Often excessive manipulation of photographs with programs such as Photoshop cause a loss in pixel information and an overall decrease in data quality, and the numerous experiments within the article examine the different approaches to preserving the information without sacrificing realistic color.
Before reading the full article I familiarized myself with the term “tone mapping” – I use Photoshop frequently and experiment with tone features, but couldn't give a precise definition. I learned tone mapping is typically descriptive of compressing HDR image information. Wikipedia defines it as a “technique used in image processing and computer graphics to map one set of colors to another in order to approximate the appearance of high dynamic range images in a medium that has a more limited dynamic range.” For example, when creating a print out image from the computer, the printer generally has a limited color/light range, making the final image less radiant than the original. IMAGER's work deals with these discrepancies in range through color reproduction.

Example of tone mapping, before and after
IMAGER proposes the following equation for color treatment in tone mapping, where C represents one color channel (i.e. red, green, or blue), L represents pixel luminance, and S for saturation. The in/out subscripts denote pixels before and after tone mapping. This formula derived from the necessity to control hue and luminance without drastically manipulating lightness or a particular color channel.

In their first experiment, researchers asked male and female participants to adjust the saturation to both a lower and higher quality while attempting to match presented original images. The results showed that desirable color saturation is complexly related to contrast compression, making definitive conclusions about the relationship between human perception and camera color detection. A second experiment demonstrated the success of preserving color appearance after contrast manipulation as opposed to the first experiment in which the manipulation occurred in the RGB realm.

Experiment results
The conclusion states “the non-linear color correction formula strongly distorts lightness but introduces less hue distortion than the luminance preserving formula, and is therefore more suitable for tone mapping,” suggesting a preference in preservation of color over lightness/darkness of the image, which can be modified through other editing software features.
This article was of interest to me because my work heavily relies on color correctness, and often I struggle in Photoshop to maintain a realistic balance between contrast, lightness, and hue. Photographers commonly over saturate their images and up the contrast to the point where their images, while beautiful, are no longer realistic. Recently I've been into food photography, and will photograph staged scenes of food I cook/bake. Such images must not be heavily manipulated at the risk of appearing unnatural or unappetizing. Learning about the techniques for preserving color while enhancing image tone will allow me to make corrections to my photographs if post-processing from the camera is necessary. Of course it is always optimal to achieve color correctness and white balance on camera, but without a proper set up or poor lighting it can be difficult to capture, making it essential for my editing to appear as seamless as possible.

Example of my photography, before & after color manipulation
Sources:
http://www.cs.ubc.ca/~heidrich/Papers/EG.09_1.pdf
http://www.secondpicture.com/tutorials/ ... pping.html
http://en.wikipedia.org/wiki/Tone_mapping
Before reading the full article I familiarized myself with the term “tone mapping” – I use Photoshop frequently and experiment with tone features, but couldn't give a precise definition. I learned tone mapping is typically descriptive of compressing HDR image information. Wikipedia defines it as a “technique used in image processing and computer graphics to map one set of colors to another in order to approximate the appearance of high dynamic range images in a medium that has a more limited dynamic range.” For example, when creating a print out image from the computer, the printer generally has a limited color/light range, making the final image less radiant than the original. IMAGER's work deals with these discrepancies in range through color reproduction.
Example of tone mapping, before and after
IMAGER proposes the following equation for color treatment in tone mapping, where C represents one color channel (i.e. red, green, or blue), L represents pixel luminance, and S for saturation. The in/out subscripts denote pixels before and after tone mapping. This formula derived from the necessity to control hue and luminance without drastically manipulating lightness or a particular color channel.
In their first experiment, researchers asked male and female participants to adjust the saturation to both a lower and higher quality while attempting to match presented original images. The results showed that desirable color saturation is complexly related to contrast compression, making definitive conclusions about the relationship between human perception and camera color detection. A second experiment demonstrated the success of preserving color appearance after contrast manipulation as opposed to the first experiment in which the manipulation occurred in the RGB realm.
Experiment results
The conclusion states “the non-linear color correction formula strongly distorts lightness but introduces less hue distortion than the luminance preserving formula, and is therefore more suitable for tone mapping,” suggesting a preference in preservation of color over lightness/darkness of the image, which can be modified through other editing software features.
This article was of interest to me because my work heavily relies on color correctness, and often I struggle in Photoshop to maintain a realistic balance between contrast, lightness, and hue. Photographers commonly over saturate their images and up the contrast to the point where their images, while beautiful, are no longer realistic. Recently I've been into food photography, and will photograph staged scenes of food I cook/bake. Such images must not be heavily manipulated at the risk of appearing unnatural or unappetizing. Learning about the techniques for preserving color while enhancing image tone will allow me to make corrections to my photographs if post-processing from the camera is necessary. Of course it is always optimal to achieve color correctness and white balance on camera, but without a proper set up or poor lighting it can be difficult to capture, making it essential for my editing to appear as seamless as possible.
Example of my photography, before & after color manipulation
Sources:
http://www.cs.ubc.ca/~heidrich/Papers/EG.09_1.pdf
http://www.secondpicture.com/tutorials/ ... pping.html
http://en.wikipedia.org/wiki/Tone_mapping
Re: Wk7 - Computational Camera
The "4EyesFace" computational photography research conducted by UCSB's very own Mathew Turk along with Changbo Hu and Rogerio Feris aims to detect, trace, and align faces in real time. They take videos of different people's faces, track the face, and then align the face to a models. They have innovated the "Active Wavelet Network" or AWN which is an algorithm used for the successful tracking and alignment of human faces. Though this is an improvement on previous programs, AWN is still sensitive to certain elements that might deform or hide certain features such as change in the way a face is illuminated on screen. Even so, this development is pretty incredible.
AWN becomes more precise based on how many wavelets are used in a reconstruction, as seen in the image below:

The reconstruction with 216 wavelets is much clearer then the one with only 52. Below, is an image of what the actual tracking and alignment of a face might look like:

AWN technology uses the Gabor wavelet network representation (GWN) to account for more texture variation, such as illumination, making the reconstructions more realistic and reliable then the previous Active Appearance Model (Tim Cootes, AAM) as discussed above. GWN tracks a face based on three variables, position, scale, and orientation and uses linear representations for maximum preserving of the image's original information.
In my own work, I think it would be interesting to experiment with this type of computational imagery. I think it would be cool to see how effectively AWN captures movements (anatomically), rather then just faces, and see how it translates the movement onto a digital image. Perhaps, one might even be able to manipulate variables in the program to create specific movements that are desired, or to create perfected movements for an art piece.
Sources:
http://www.cs.cmu.edu/~changbo/publications/AWN.pdf
http://ilab.cs.ucsb.edu/index.php/compo ... icle/12/34
AWN becomes more precise based on how many wavelets are used in a reconstruction, as seen in the image below:
The reconstruction with 216 wavelets is much clearer then the one with only 52. Below, is an image of what the actual tracking and alignment of a face might look like:
AWN technology uses the Gabor wavelet network representation (GWN) to account for more texture variation, such as illumination, making the reconstructions more realistic and reliable then the previous Active Appearance Model (Tim Cootes, AAM) as discussed above. GWN tracks a face based on three variables, position, scale, and orientation and uses linear representations for maximum preserving of the image's original information.
In my own work, I think it would be interesting to experiment with this type of computational imagery. I think it would be cool to see how effectively AWN captures movements (anatomically), rather then just faces, and see how it translates the movement onto a digital image. Perhaps, one might even be able to manipulate variables in the program to create specific movements that are desired, or to create perfected movements for an art piece.
Sources:
http://www.cs.cmu.edu/~changbo/publications/AWN.pdf
http://ilab.cs.ucsb.edu/index.php/compo ... icle/12/34
Re: Wk7 - Computational Camera
Yoav Schechner and Nir Karpel researched a way to get clear underwater vision. They explained that underwater imaging is important for scientific research and technology but also can be used for recreational purposes. The research started when they noticed that the computers visions were degraded when taken underwater, the visibility was not as good. The reason for this, they explored, were because the underwater conditions are not as easy to work with, specifically motions are limited and image mapping is a lot more complicated underwater. In the article Schechner and Karpel published, they described what it was like to try and recover the image using image enhancing tools but “Since they do not model the spatially varying distance dependencies, traditional methods are of limited utility in countering visibility problems..” In other words, the quality of the photo is downgraded because the image enhancing tools are unable to complete the photo realistically. The picture below is an example of a before and after editing.
By looking at the picture, we can see that after the person edited the photo and it turned out more green overall. Although we can see more details of the turtles but meanwhile the other elements were changed.
For usage in art, this underwater picture could come in handy for paintings or other forms of artwork. For me personally, this would be helpful to know because I would like to try and scuba down as far as I could and take some wonderful pictures of wildlife and animals. It’s helpful to know how to photo map efficiently or to take a photo efficient enough so that I can take a good shot. Also other photographers and computer designers can learn the different techniques to benefit.

Source:
http://webee.technion.ac.il/~yoav/publi ... nveil2.pdf
For usage in art, this underwater picture could come in handy for paintings or other forms of artwork. For me personally, this would be helpful to know because I would like to try and scuba down as far as I could and take some wonderful pictures of wildlife and animals. It’s helpful to know how to photo map efficiently or to take a photo efficient enough so that I can take a good shot. Also other photographers and computer designers can learn the different techniques to benefit.
Source:
http://webee.technion.ac.il/~yoav/publi ... nveil2.pdf
Last edited by ashleyf on Tue Nov 13, 2012 9:26 am, edited 1 time in total.